
1.6 million QPS with MDB-10.6
We all love MariaDB Server for its features and performance. Lately, it further improved it through a series of optimization (in 10.6) around locking, flushing, etc… So we decided to give it a try and also analyze its performance with more numa nodes (4 numa nodes). Article enlist, issues faced on the numa scalability front, solution adopted and how it helped hit the threshold of 1.6 millions QPS for query workload.
NUMA scalability and associated challenges
We started studying MariaDB server (MDB) performance using the latest development branch that is 10.6 given it has fixes that resolves some of the crucial locking and flushing issues there-by making it a good starting point with basic issues taken-care of.
Study could be divided into 2 parts:
- Read-Only workload (point-select, read-only)
- Read-write workload (update and non-update index)
As part of the said article, we will discuss read-only workload and related fixes. In due course, we will have another article about read-write workload.
Before we get into finer details some notes about NUMA scalability.
What is numa scalability?
- Normally, we observe that performance of a well tuned software continues to grow with increasing compute power. Any bottleneck in this trajectory is tagged as a scalability bottleneck that mainly arises due to io or cpu hitting threshold.
- What if we tell you that there is enough compute power (no io bottleneck) but still software fails to scale? Infact, with increasing compute power (in turn more resources) there is a regression.
- These are NUMA scalability challenges. Despite doubling the compute power there is a drop in overall throughput.
Is NUMA avoidable?
- There is a limit to how much a single processor could scale upto. Most of the server class processors these days have an average frequency in the range of 2.5-3 Ghz with N cores (turbo mode that could scale further by 20-30%).
- With softwares becoming compute intensive there is a need for more processing power and of-course it comes by adding more CPUs on the board there-by enabling the NUMA model.
- Unfortunately, this horizontal scaling introduces its own set of challenges around memory sharing, cache line sharing, cross numa data movement and latency, etc…
- The performance of the software depends a lot on data placement and ability to localize the data-processing to the local numa nodes. With shared/global variables, issues like cross-numa access and cache line sharing start to boil up.
- Fortunately, most of the advanced software like MariaDB, MySQL server are able to successfully tackle these challenges by introducing sharded mutex, distributed counter, cache line padding, fine grained resource locking etc…
For the experiment below we have used a 4 numa node Kunpeng 920 (ARM) based bare metal machine that has 128 cores so each numa node has 32 cores. (1 numa: 32 cores, 2 numa: 64 cores, 4 numa: 128 cores). Data is complete in memory and allocated in interleaved fashion. Cross NUMA latency: 1 -> 1 (10), 1 -> 2 (16), 1 -> 3 (32), 1 -> 4 (33). So cross-numa latency is in the range of 60-230%.
Analyzing Read-only workload
point_select:
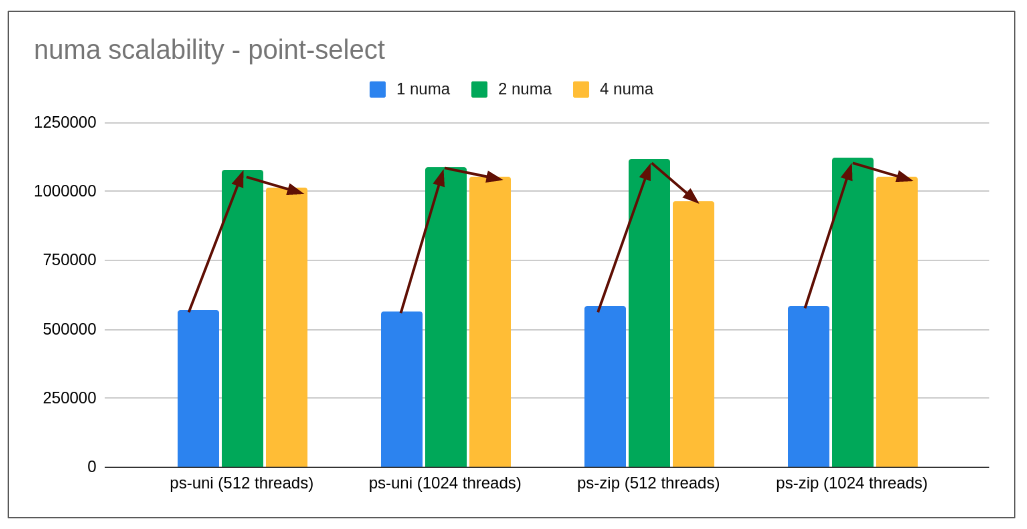
- As expected, things scaled well from 1 numa node to 2 numa nodes (90% improvement) but when moved from 2 numa nodes to 4 numa nodes there is a sudden drop in qps (by 10-15%). This was surely not expected given double the number of cores. (Pattern is observed irrespective of contention (uni: uniform, zip: zipfian)).
read_only:
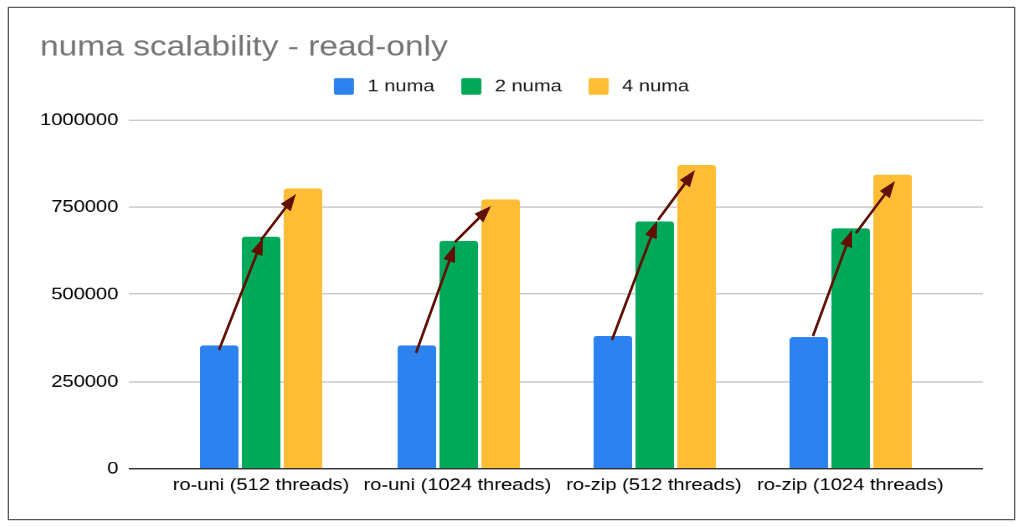
- With read-only too, moving from 1 numa node to 2 numa nodes scales well (gain of 86%) but again while moving from 2 numa to 4 numa there is limited gain (of 20% only). (Fortunately no regression like in point-select).
what perf has to say?
perf pointed 2 major problems.
- hotspot in buf_page_get_low which is arising due to a global counter (already reported at MDEV-21212).
- mutex wait (now majority of the mutexes are pthread based so mutex wait is reported in the form of kernel functions). (MDEV-25029)
point-select
+ 12.12% 13470 mysqld [kernel.kallsyms] [k] queued_spin_lock_slowpath
+ 4.98% 5306 mysqld [kernel.kallsyms] [k] __wake_up_common_lock
+ 4.63% 251900 mysqld [kernel.kallsyms] [k] finish_task_switch
+ 4.36% 4523 mysqld mariadbd [.] buf_page_get_low
read-only
+ 10.60% 10453 mysqld mariadbd [.] buf_page_get_low
+ 3.95% 238280 mysqld [kernel.kallsyms] [k] finish_task_switch
+ 3.81% 2985 mysqld mariadbd [.] row_search_mvcc
+ 3.35% 2312 mysqld mariadbd [.] buf_page_optimistic_get
To find out which mutex is hot we resorted to performance-schema. Surprisingly, the top hot mutex is dict_sys mutex despite being a read-only workload (dict_sys is normally involved when table metadata changes).
+--------------------------------------------------+---------------+------------+
| EVENT_NAME | WAIT_MS | COUNT_STAR |
+--------------------------------------------------+---------------+------------+
| wait/synch/mutex/innodb/dict_sys_mutex | 37122423.2766 | 101897091 |
| wait/synch/mutex/innodb/buf_pool_mutex | 98582.4349 | 8232742 |
| wait/synch/mutex/innodb/fil_system_mutex | 1111.6186 | 4245171 |
- What dict_sys has to do with read-only workload? Well, queries read table metadata that is protected by the global mutex acquired at-least once per query ((dict_sys: dict_sys.mutex_lock, dict_sys.mutex_unlock from, info_low)). 1024 threads with 1 million qps you can imagine the possible contention.
- Unfortunately, cache aligning the mutex is not going to help as it is real contention.
- Fortunately, MDB-10.6 introduces a table level lock_mutex that is meant to protect the locks on the table and it could be safely re-used while updating/reading the stats.
performance with issues fixed:
Let’s analyze performance after resolving both of these issues
point_select:
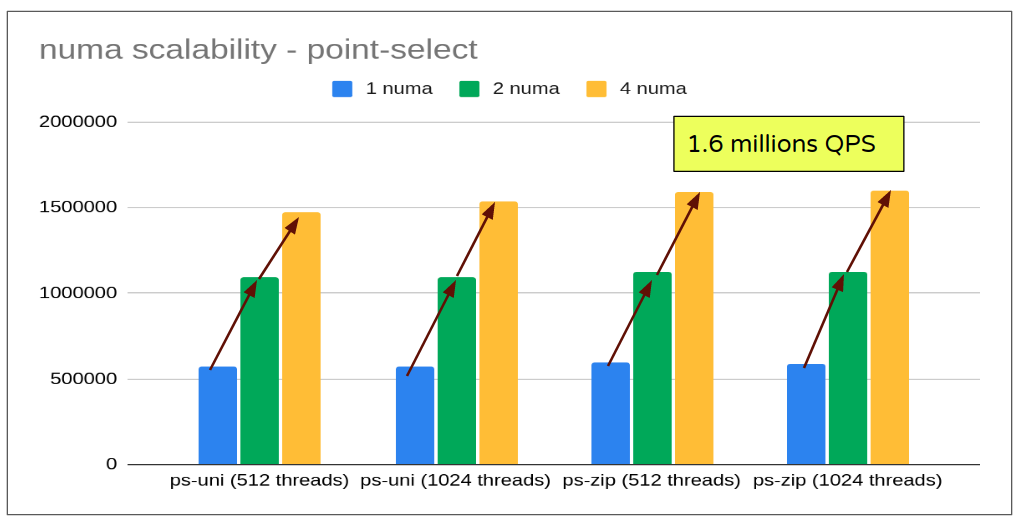
- With the said fix, point-select performance improved to cross 1.6 millions QPS mark (from regression of 10-15% to a gain of 42%). Also, 2 numa qps continue to hover around the same level. This reveals numa specific issues that are observed only with more numa nodes.
read-only:
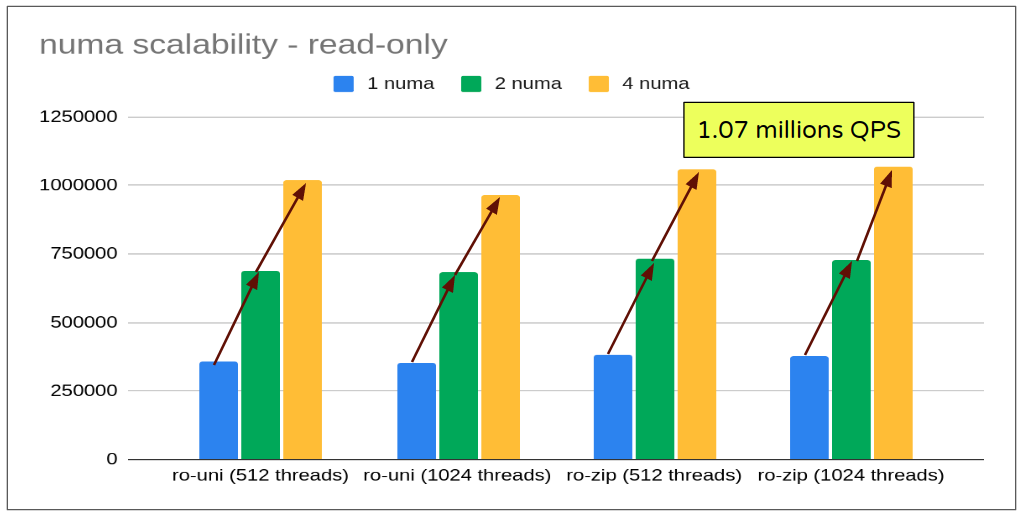
- Even with read-only workload, there is a substantial increase in qps for 4 numa nodes (from limited gain of 20% to an improved gain of 50%). Again, no major difference with 2 numa nodes, re-confirming the numa scalability issues.
what perf has to say now?
point-select
+ 5.48% 266068 mysqld [kernel.kallsyms] [k] finish_task_switch
+ 5.33% 4773 mysqld [kernel.kallsyms] [k] __wake_up_common_lock
+ 4.05% 3945 mysqld mariadbd [.] rec_get_offsets_func
+ 4.03% 3783 mysqld mariadbd [.] buf_page_get_low
..
0.50% 460 mysqld [kernel.kallsyms] [k] queued_spin_lock_slowpath
read-only
+ 6.08% 158633 mysqld [kernel.kallsyms] [k] finish_task_switch
+ 4.26% 3191 mysqld mariadbd [.] row_search_mvcc
+ 3.57% 3704 mysqld [kernel.kallsyms] [k] __wake_up_common_lock
+ 3.33% 2439 mysqld libc-2.17.so [.] _wordcopy_fwd_dest_aligned
+ 2.97% 2850 mysqld mariadbd [.] rec_get_offsets_func
Performance schema too confirms the fact
+--------------------------------------------------+-----------+------------+
| EVENT_NAME | WAIT_MS | COUNT_STAR |
+--------------------------------------------------+-----------+------------+
| wait/synch/mutex/innodb/dict_sys_mutex | 3156.9215 | 13160 |
| wait/synch/mutex/innodb/buf_pool_mutex | 2115.6082 | 8228226 |
| wait/synch/mutex/innodb/fil_system_mutex | 688.2885 | 4242913 |
Both of these fixes are now folded to MariaDB Server 10.6 trunk.
Conclusion
As we saw above NUMA introduces its own set of challenges and is often observed only with increasing numa nodes. This also means some of these fixes are justifiable only with increasing scalability. In future, the number of numa nodes are set to increase so any new changes should now be designed keeping in mind the NUMA scalability effect.
If you have more questions/queries do let me know. Will try to answer them.