
A configuration that can double MySQL write performance
MySQL is heavily tunable and some of the configuration can have significant impact on its performance. During my experiment for numa scalability I encountered one such configuration. Default configuration tends to suggest heavy contention for write workload but once tuned it helps scale MySQL by more than 2x.
Understanding the problem
I started testing write-workloads with different numa levels (1 numa [32 cores]/2 numa [64 cores]/ 4 numa [128 cores]) and observed a weird behavior.
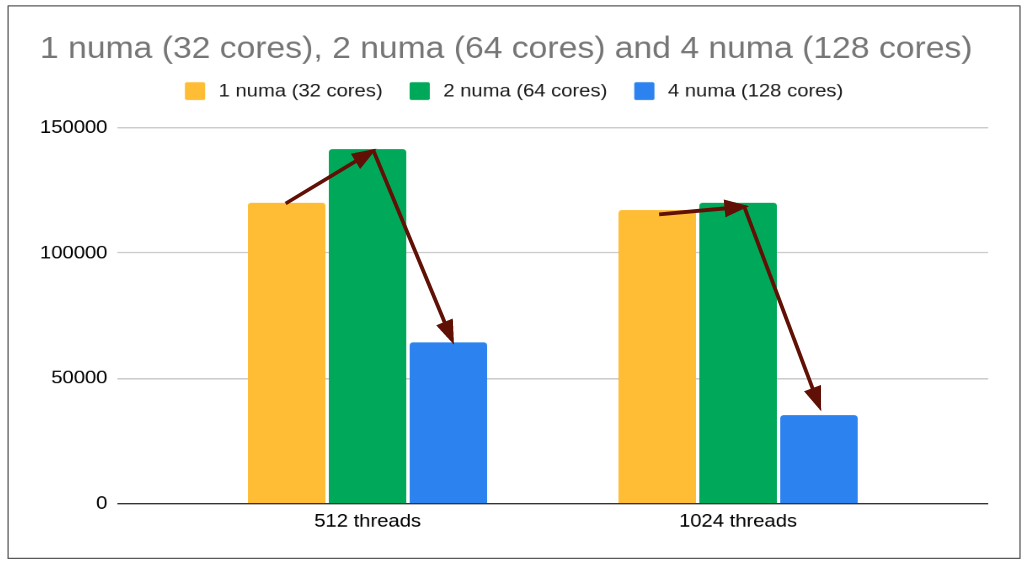
- With increasing compute power we expected throughput to grow. The pattern is observed when we move from 1 numa to 2 numa but there is significant throughput loss (despite double compute power) when switched from 2 numa to 4 numa.
- This is exactly what we call as NUMA SCALABILITY BOTTLENECK (vs a SCALABILITY BOTTLENECK that tends to achieve optimal performance with a given set of compute and io resources).
server: mysql-8.0.24.
configuration: click here (+ skip-log-bin)
machine: ARM machine (kunpeng 920 (2 sockets, 128 cores, 4 numa nodes), nvme ssd)
workload: sysbench update-index (cpu-bound)
Identifying the bottleneck
To get more insight on contention I resorted to perf-schema.
+-----------------------------------------------+---------------+------------+
| EVENT_NAME | WAIT_MS | COUNT_STAR |
+-----------------------------------------------+---------------+------------+
| wait/synch/mutex/innodb/trx_sys_mutex | 28341923.1285 | 8637971 |
| wait/synch/mutex/innodb/undo_space_rseg_mutex | 24417716.9238 | 3895877 |
| wait/synch/mutex/innodb/sync_array_mutex | 3619893.6460 | 38717477 |
+-----------------------------------------------+---------------+------------+
3 rows in set (0.05 sec)
Surprisingly the 2nd most contended mutex is rollback segment mutex. (1st being trx_sys that is a known issue and mysql hopefully is working on it to make trx_sys lock-free).
Fortunately, there is a way out.
undo tablespaces
MySQL has been working on improving the undo tablespace framework for quite some time, starting with undo tablespace truncation (and I am fortunate enough to code it back in 5.7x timeframe). I still remember discussing the limitation of the 128 rollback segments but given it would need major change it was deferred to 8.x and eventually it came with 8.x (changes around 8.0.14 and then again 8.0.23) where-in user can now configure extra undo tablespaces and that in turn defines number of rollback segments.
Here is the latest and simplified view:
InnoDB will create 2 default undo tablespaces (also known as implicit tablespaces)
Users can add 125 (maximum) undo tablespaces (also known as explicit tablespaces).
Total: 127 undo tablespaces.
Each undo tablespace can host 128 rollback segments (controlled using innodb_rollback_segments).
So 127 * 128 = 16256 rollback segments are available for transactions.
mysql> show status like '%undo%';
+----------------------------------+-------+
| Variable_name | Value |
+----------------------------------+-------+
| Innodb_undo_tablespaces_total | 127 |
| Innodb_undo_tablespaces_implicit | 2 |
| Innodb_undo_tablespaces_explicit | 125 |
| Innodb_undo_tablespaces_active | 127 |
+----------------------------------+-------+
4 rows in set (0.00 sec)
(It is just 128 rollback segments in 5.7. Starting 8.x given 2 default undo tablespaces 256 rollback segments are made active by default)
Resolving Contention
So with default 2 undo-tablespaces only 256 rollback segments are made active and N transactions will share these rollback segments. With N = 150K approximately 586 transactions use the same rollback segments creating heavy contention as all of them need the said mutex latch in order to add their undo-logs to transaction history during commit stage (check trx_write_serialisation_history for more details).
If we create additional 125 explicit undo tablespaces it would make 127 * 128 = 16256 rollback segments that is around 9 transactions per rollback segment significantly reducing the contention.
Let’s see if this solution helps.
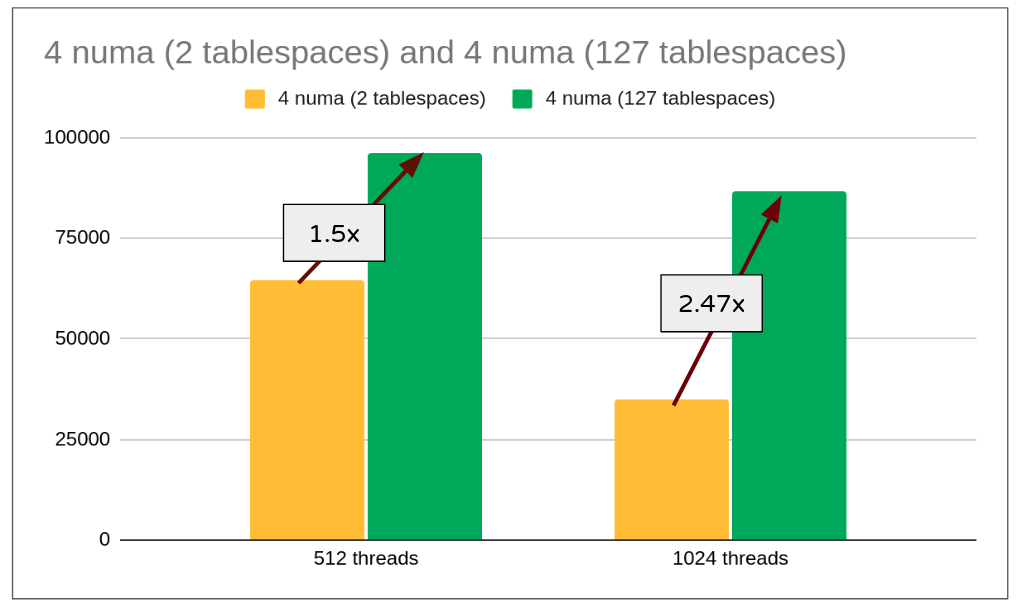
Same could be confirmed with perf schema output
With 2 undo tablespaces:
+-----------------------------------------------+---------------+------------+
| EVENT_NAME | WAIT_MS | COUNT_STAR |
+-----------------------------------------------+---------------+------------+
| wait/synch/mutex/innodb/trx_sys_mutex | 88168453.5988 | 19540096 |
| wait/synch/mutex/innodb/undo_space_rseg_mutex | 78933376.9118 | 14811159 |
| wait/synch/mutex/innodb/sync_array_mutex | 11274812.8370 | 111143905 |
+-----------------------------------------------+---------------+------------+
3 rows in set (0.04 sec)
With 127 undo tablespaces:
+-------------------------------------------------+----------------+------------+
| EVENT_NAME | WAIT_MS | COUNT_STAR |
+-------------------------------------------------+----------------+------------+
| wait/synch/mutex/innodb/trx_sys_mutex | 153155037.4916 | 33537120 |
| wait/synch/mutex/innodb/buf_pool_LRU_list_mutex | 18706130.3456 | 38819242 |
| wait/synch/mutex/innodb/sync_array_mutex | 4240650.4708 | 93054607 |
+-------------------------------------------------+----------------+------------+
3 rows in set (0.08 sec)
| wait/synch/mutex/innodb/undo_space_rseg_mutex | 213977.8787 | 31464777 |
Wait has reduced from 78933376 milli-seconds (77 seconds per thread) to 213977 milli-seconds (0.2 seconds per thread).
Fallback (if any?)
Approach of increasing undo tablespace is really good but enabling 125 explicit tablespaces consumes disk space and to keep this in limit users should configure undo tablespace truncate.
Default innodb_max_undo_log_size = 1GB assuming all 127 tablespaces are growing uniformly, truncate will not kick in till all of them are around 1GB in size there-by consuming 127GB of the disk space.
If you plan to enable 127 tablespaces then better is to reduce the innodb_max_undo_log_size (unless disk space is not a concern).
Effect of enabling 127 tablespaces on lesser numa nodes
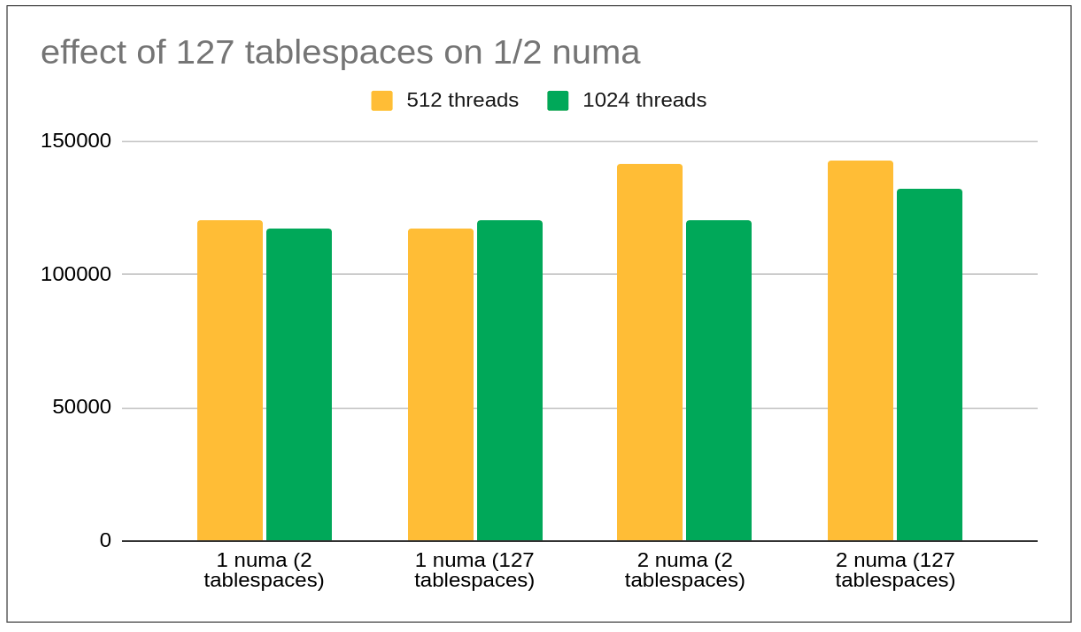
As we could see there is negligible/marginal effect on enabling 127 tablespaces for lower numa nodes. NUMA scalability fix/solution effects are observed with increased numa nodes but minimal change is observed for lower numa nodes. We can have a separate blog post about NUMA scalability explaining why such effects are observed.
Conclusion
Scaling MySQL for NUMA has its own challenges and while the solution for some of these problems pre-exist extra configuration may be needed. It would be really helpful if MySQL can auto detect and configure some of these limits based on the numa configuration it is running on.
If you have more questions/queries do let me know. Will try to answer them.