
ARM's LSE (for atomics) and MySQL
ARM introduced LSE (Large System Extensions) as part of its ARMv8.1 specs. This means if your processor is ARMv8.1 compatible it would support LSE. LSE are meant to optimize atomic instructions by replacing the old styled exclusive load-store using a single CAS (compare-and-swap) or SWP (for exchange), etc…. Said extensions are known to inherently increase performance of applications using atomics.
Understanding LSE
To better understand LSE let’s take a working example to see how the code is generated and possible optimization.
LSE turned off


As you can see there is a loop for doing CAS. Load the value, check with expected value and if different then store the value. Main loop is a 5 step process with 2 exclusive instructions with respective memory ordering. SWAP too has a loop for checking if the store is successful.
ARM has multiple variant of load/store instructions so before we proceed let’s take a minute to understand these variants.

stlxrb: store exclusive with release semantics/ordering. Provide exclusive access to the said cache line. “b” represents byte. (other variant half-word (2), word(4), double-word (8)).
stlrb: store with release semantics/ordering helping suggest ordering semantics only but not exclusive access.
strb: normal store to a non-atomic variable (no ordering semantics)
Naturally one may ask how come both seq-cst and release memory order generate the same asm instruction. This is because store-release in ARM-v8 is multi-copy atomic, that is, if one agent has seen a store-release, then all agents have seen the store-release. There are no requirements for ordinary stores to be multi-copy atomic. [Something similar to mov+fence or xchg in x86_64 domain].
LSE turned on
So let’s now see what would happen if we now turn-lse on. LSE support was added with ARM-v8.1 specs and so if the default compilation is done, gcc will try to make binary compatible with a wider aarch64 processors and may not enable the specific functionality. In order to enable lse user need to specify extra compilation flags:
There are multiple ways to turn-on lse:
- Compile with gcc-6+ by specifying lse flag as -march=armv8-a+lse
- Compile with gcc-6+ by specifying ARMv8.1 (or higher) (that will auto-enable all ARMv8.1 functionalities). -march=armv8.1-a

No more while loop. Single instruction (CASALB) to do the compare and swap (that takes care of load and store) and same way SWAPLB to do the exchange. Sounds optimized. More about performance below.
But there is one problem, what if binaries are compiled with +lse support but the target machine doesn’t support lse as it is only arm-v8 compatible. This problem is solved with gcc-9.4+ by introducing -moutline-atomics (default enabled with gcc-10.1 can be disabled with -mno-outline-atomics). GCC auto emits a code with dynamic check with both variants (lse and non-lse). Runtime a decision is taken and accordingly said variant is executed.
Let’s see what is emitted if compiled with gcc-10 (with -moutline-atomic making it compatible on all aarch64 machines)
| code | asm (perf output) |
|---|---|
| bool expected = true; flag.compare_exchange_strong(expected, false); |
<__aarch64_cas1_acq_rel>: __aarch64_cas1_acq_rel(): │ adrp x16, 11000 <__data_start> │ ldrb w16, [x16, #25] │ ↓ cbz w16, 14 │ casalb w0, w1, [x2] │ ← ret │14: uxtb w16, w0 │ 18: ldaxrb w0, [x2] │ cmp w0, w16 │ ↓ b.ne 2c │ stlxrb w17, w1, [x2] │ ↑ cbnz w17, 18 │2c: ← ret |
Notice the branching instruction (highlighted in green) to select appropriate logic.
LSE in action
While all this sounds interesting but does it really help? What if the new instruction takes more cycles. Only one way to find out: Benchmark.
Benchmark: Simple spin-mutex with each thread (total N threads) trying to get the lock there-by causing heavy contention. Once the thread has the mutex it performs software based crc32 keeping the cpu bit busy before releasing it. Each thread does this M times.
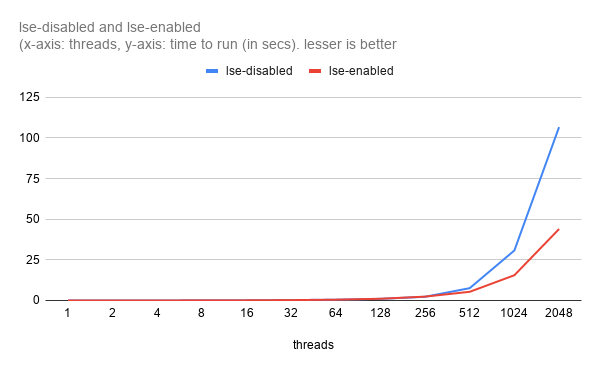
- Use-case represent a serious contention with each thread mostly spending time for obtaining lock. Workload as such is pretty quick (crc32 on 16KB block).
- This clearly proves that LSE helps in heavily contented cases.
But micro-benchmark sometime fails to show the needed gain with original application due to nature of application including other overlap components like IO, other processing element, etc… So let’s now evaluate MySQL performance with lse-enabled.
MySQL benchmarking with LSE
Workload:
- Server: MySQL-8.0.21, OS: CentOS-7
- Sysbench based point-select, read-only, read-write, update-index and update-non-index workload.
- Executed for higher scalability (>= 64) to explore contention.
- Configuration: 32 cores (single NUMA) ARM Kunpeng 920 2.6 Ghz (28 cores for server, 4 for sysbench)
- Tried 2 use-cases uniform, zipfian (more contention)
- baseline=lse-disabled, lse=lse-enabled (-march=armv8-a+lse).
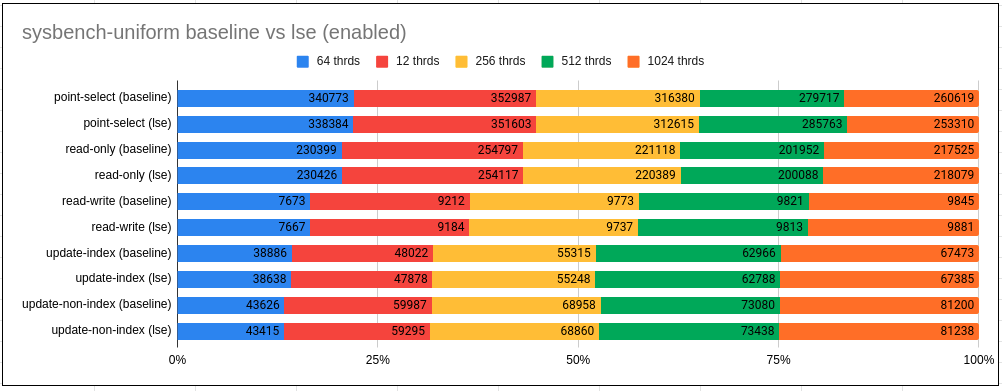
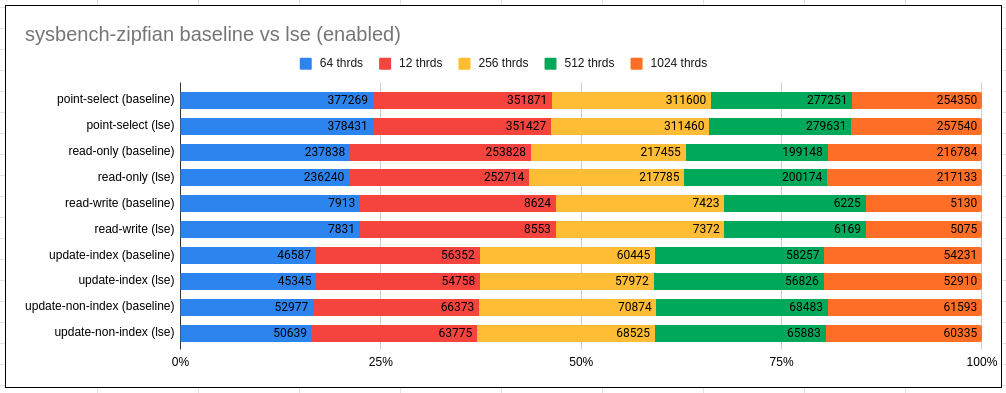
Observations:
- With Uniform we hardly see any difference with use of LSE
- With Zipfian LSE tend to regress marginally but consistently (by 2-4%) for update use-cases.
Conclusion
LSE as feature looks promising but fails to perform in MySQL use-case. May be once MySQL is tuned to use more atomics, LSE could show a +ve difference. Till then nothing we would not loose if LSE is not enabled.
If you have more questions/queries do let me know. Will try to answer them.