
NUMA Smart Global Counter (inspired from MySQL)
Managing global counters in a multi-threaded system has always been challenging. They pose serious scalability challenges. Introduction of NUMA just increased the complexity. Fortunately multiple options have been discovered with hardware lending support to help solve/ease some of these issues. In this blog we will go over how we can make Global Counter NUMA SMART and also see what performance impact each of this approach has.
Note: a lot of this work is inspired from MySQL codebase that is continuously trying to evolve to solve this issue.
Global Counters
Most of the software (for example: database, web-server, etc…) needs to maintain some global counters. Being global, there is one copy of these counters and multiple worker threads try to update it. Of-course this invites a need of coordination while updating these copies and in turn it becomes scalability hotspots.
Alternative is to loosely maintain these counters (w/o any coordination) but that means they will represent an approximate number (especially on a heavily contended system). But they have their own benefits.
Let’s see what all approaches the current ecosystem provides to help solve this problem.
Setup
In order to evaluate different approaches we will consider a common setup.
- Let’s consider some global counters that are at global level so all threads update them once in a while.
- Let’s consider some data-blocks (where the real workload happens) and as part of this action global counters are updated. Each data-block has its own local counter(s). These local counters are updated whenever data-block is accessed. Both of these blocks are interleaved. Check the arrangement below.
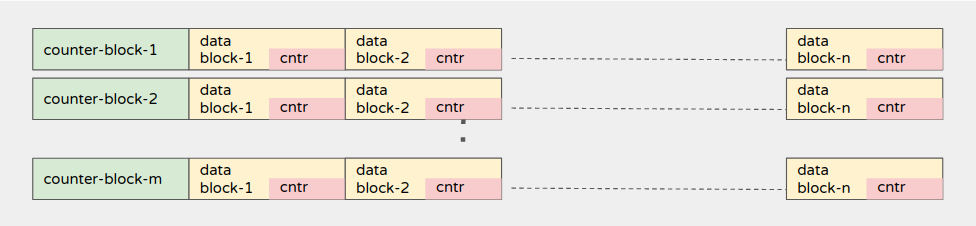
- Let’s try to understand this structure with some simple numeric examples.
- Say we have 100 global counter-blocks and each data-block has 10 counters.
- Say we have 1000 global data-blocks that are equally interleaved with each counter block.
- That means, 1-counter-block is followed by 10-data-blocks and this combination repeats 100 times.
- This ensures complete memory blocks are distributed across NUMA nodes and we get to see the effect of NUMA while accessing the counters and data-blocks too.
- Workload (one-round):
- Flow will access N data-blocks (at-least enough to invalidate L2 cache).
- As part of the data-block access, local counter(s) associated with the data-block are also updated. Data blocks are randomly selected using rand() function to ensure spread-across distribution.
- This is followed with the access and update of global counters from the counter-block. Random counter-block is selected and a random counter from the selected counter block is updated (inc operation). This operation is repeated M times.
- Workload loop is repeated K times (rounds).
- Each thread executes the said workload loop (K times). Benchmarking is done with different scalability starting from 1-256/2048.
Note: Counter is simply uint64_t value (currently using inc operation only).
If you are interested in understanding more about this you can always check out the detailed code here.
Hardware used
For scaling from 1-256
- x86-vm: 24 vCPU (12 cores with HT), 48 GB memory, 2 NUMA nodes, Intel(R) Xeon(R) Gold 6266C CPU @ 3.00GHz (Ubuntu-18.04)
- arm-vm: 24 vCPU (24 cores), 48 GB memory, 2 NUMA nodes, Kunpeng 920 2.60 GHz (Ubuntu-18.04)
For scaling from 1-2048
- arm-bms: 128 physical cores, 1 TB of memory, 4 NUMA nodes, Kunpeng 920 2.60 GHz (CentOS-7.8)
Idea is not to compare x86 vs ARM but the idea is to compare the effect of NUMA on the global counter.
Approches
As part of the experiment we evaluated different approaches right from basic to advanced.
- pthread-mutex based: Simple pthread mutexes that protects operation on counter
- std::mutex: C++11 enabled std::mutexes just like pthread mutexes but more easier to use with inherent C++11 support.
- std::atomic: C++11 atomic variable.
- fuzzy-counter (from mysql): There are N cacheline aligned slots. Flow randomly selects one of the slots to update. To find out the total value of the counter, add value from all the slots. There are no mutexes/atomic that protect the slot operations. This means value is approximate but works best when the flow needs likely count. We will see a variance factor below in result section. [ref: ib_counter_t. N is typically = number of cores].
- shard-atomic-counter (from mysql): Counter is split into N shards (like slot above). Each flow tells which shard to update. Shards are cache lines aligned for better access. [ref: Counter::Shard]
- shard-atomic-counter (thread-id based): Counter is split into N shards (like slot above). Shard to update is selected based on thread-id of executing thread. Shards are cache lines aligned for better access. [here N is number-of-active-cores]
- shard-atomic-counter (cpu-id based): Counter is split into N shards. Shard to update is selected based on core-id of executing core. Shards are cache lines aligned for better access. [here N is number-of-active-cores. cpu-id obtained using sched_getcpu].
- shard-atomic-counter (numa-id based): Counter is split into N shards. Shard to update is selected based on numa-node-id of the executing core. Shards are cache lines aligned for better access. [here N is number-of-active-numa-nodes. N is small here in the range of 2/4/8 not like 32/64/128/etc…]
There is another counter structure inside MySQL that is worth mentioning ut_lock_free_cnt_t(). It tries to allocate memory for each counter (value) on respective NUMA but as per the numa_alloc_onnode even a smaller chunk of 8 bytes will cause allocation of system-page size (for Linux 4KB). That is too much space wastage. I tried this approach but eventually failed to allocate memory due to enormous memory over-head.
Idea is to find out which approach works best in the NUMA environment.
Benchmarking
Benchmarking is done using the structure and workload explained above. Each run allocates memory and then K rounds of workload loop per scalability. Timing below includes time to process data and counter but majority of it is coming from counter contention (confirmed by supressing data-block processing).
- x86-vm [x-axis: threads(1-256), y-axis: time in seconds. Lesser is best]
Data-set: 100 global counter blocks, 10 counters per block, 1m data-blocks (with a local counter per block), 10K rounds
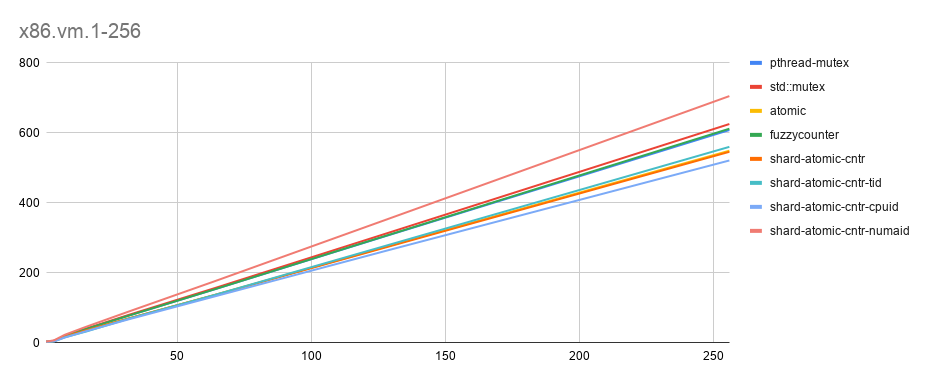
Comments
- As expected, shard-atomic-counter with cpu-id performs best. (cpu-id = sched_getcpu).
- Suprisingly, simple atomic is optimal too with significant space saved. (No cacheline alignment). May be VM effect.
- Another unexplained behavior: fuzzy counter which is expected to be fastest is not showing up to be fastest (I re-confirmed this behavior with 3 different runs. On ARM, it performing as expected so less likely something going wrong in the benchmarking code. More analysis to be done).
Lines are pretty close/overlapping, so sharing the numeric numbers for higher-sclalability.
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 305.89 | 312.78 | 275.21 | 306.62 | 273.52 | 278.14 | 263.5 | 352.45 |
| 256 | 608.21 | 625.37 | 549.15 | 611.97 | 546.04 | 560.18 | 521.25 | 705.17 |
- arm-vm [x-axis: threads(1-256), y-axis: time in seconds. Lesser is best]
Data-set: 100 global counter blocks, 10 counters per block, 1m data-blocks (with a local counter per block), 10K rounds
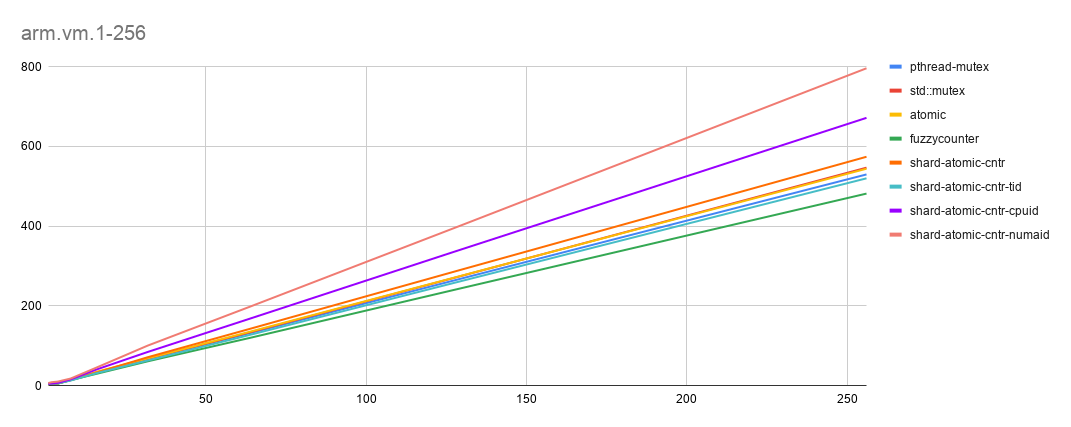
Comments
- Again, shard-atomic-counter (this time with thread-id) scored better than other alternatives. (one of the reason could be sched_getcpu is costly on ARM). [For thread-id, flow cached thread unique identifier during creation, in thread-local storage].
- FuzzyCounter is helping establish baseline (given there is no-contention).
- Good old pthread-mutex seems to be optimized too.
- Intererstingly, ARM seems to be showing lower contention with increase scalability (may be due to better NUMA interconnect).
Lines are pretty close and in some cases overlapping too, so sharing the numeric numbers for higher-sclalability.
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 265.05 | 271.53 | 272.06 | 241.26 | 287.1 | 258.9 | 337.2 | 396.88 |
| 256 | 529.74 | 546.74 | 544.07 | 481.71 | 574.05 | 520 | 671.63 | 795.92 |
- arm-bms [x-axis: threads(1-2048), y-axis: time in seconds. Lesser is best]
Data-set: 100 global counter blocks, 10 counters per block, 1m data-blocks (with a local counter per block), 1K rounds
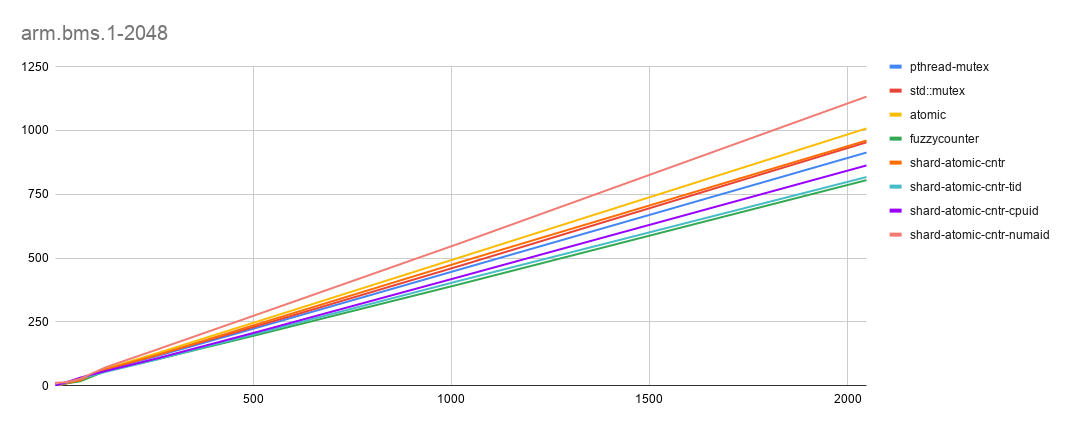
Comments
- Fuzzy-Counter help set the baseline but this time we see shard-atomic-counter (with thread-id) is almost on-par with Fuzzy-Counter (non-contention use-case). That is like optimal number to expect.
Lines are pretty close and in some cases overlapping too, so sharing the numeric numbers for higher-sclalability. Just incase you have not noticed the rounds has been reduced by 1K. Keeping it 10K increases timing like anything due to cross-numa access and increased scalability. (note: we are now on operating machine with 4 numa nodes).
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 62.81 | 63.9 | 66.24 | 57.37 | 64.24 | 54.09 | 57.67 | 72.08 |
| 256 | 115.39 | 119.53 | 126.52 | 102.68 | 119.01 | 102.13 | 106.3 | 140.83 |
| 512 | 228.2 | 234.5 | 252 | 199.71 | 241.69 | 205.66 | 211.29 | 279.81 |
| 1024 | 456.53 | 470.55 | 503.73 | 398.61 | 484.82 | 412.43 | 427.52 | 559.21 |
| 2048 | 913.58 | 953.56 | 1007.94 | 805.35 | 960.53 | 817.45 | 862.94 | 1132.56 |
Let’s see approximation factor for fuzzy-counter. Not that major difference.
| threads | global-counter (expected) | global-counter (actual) |
|---|---|---|
| 128 | 20480000 | 20479994 |
| 256 | 40960000 | 40959987 |
| 512 | 81920000 | 81919969 |
| 1024 | 163840000 | 163839945 |
| 2048 | 327680000 | 327679875 |
Conclusion
Benchmark study has proved that using CPU/thread affinity for global counters works best. Of-course x86 and ARM has different optimization point so MySQL could be tuned accordingly. Fuzzy counter could be better replaced with atomic (or shard-atomic) given space saved and improved accurancy (on x86).
If you have more questions/queries do let me know. Will try to answer them.