
Understanding Memory-Barrier with MySQL EventMutex
MySQL has multiple mutex implementations viz. wrapper over pthread, futex based, Spin-Lock based (EventMutex). All of them have their own pros and cons but since long MySQL defaulted to EventMutex as it has been found to be optimal for MySQL use-cases.
EventMutex was switched to use C++ atomic (with MySQL adding support for C++11). Given that MySQL now also support ARM, ensuring a correct use of memory barrier is key to keep the EventMutex Optimal moving forward too.
In this article we will use an example of EventMutex and understand the memory barrier and also see what is missing, what could be optimized, etc…
Understanding acquire and release memory order
ARM/PowerPC follows weak memory model that means operations can be re-ordered more freely so ensuring the correct barrier with synchronization logic is important. Easiest alternative is to rely on a default one that uses sequential consistency (as done with x86) but it could affect performance big time on other architectures.
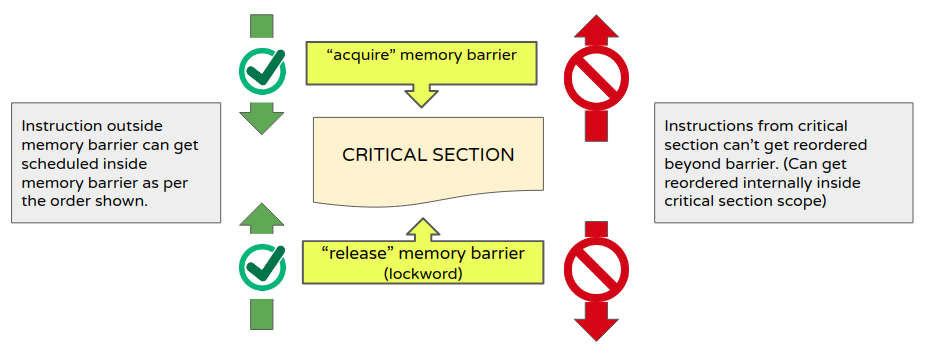
Often a programmer has to deal with 2 barriers (aka order): acquire and release.
- acquire memory order means any operation after this memory-order/barrier can’t be scheduled/re-ordered before it (but operations before it can be scheduled/re-ordered after it)
- release memory order means any operations before this memory-order/barrier can’t be scheduled/re-ordered after it (but operations after it can be scheduled/re-ordered before it).
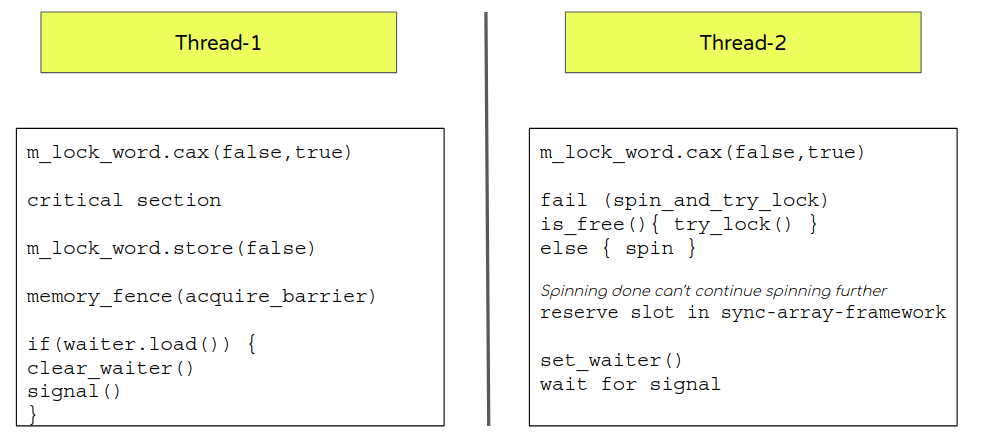
Understanding EventMutex structure
EventMutex provides a normal mutex-like interface meant to help synchronize access to the critical sections.
- Enter (lock mutex)
- try_lock (try to get the lock if procured return immediately).
- Uses an atomic variable (m_lock_word) that is set using compare-and-exchange (CAX) interface.
- If fail to procure
- Enter a spin-loop that does multiple attempts to pause followed by check if the lock is again available.
- If after “N” attempts (controlled by innodb_sync_spin_loops) lock is not available then yield (releasing the cpu control) and enter wait by registering thread in InnoDB home-grown sync array implementation. Also, set a waiter flag after reserving the slot (this ensures we will get a slot in sync-array). Waiter flag is another atomic that is used to coordinate the signal mechanism.
- try_lock (try to get the lock if procured return immediately).
- Exit (unlock mutex)
- Toggling the atomic variable (m_lock_word) to signify leaving the critical section.
- Check if the waiter flag is set. If yes then signal the waiting thread through the sync-array framework.
Looks pretty straightforward and simple. Isn’t it?
Things get complicated with introduction of memory barriers as ignoring them would mean re-ordering can cause race in your code.
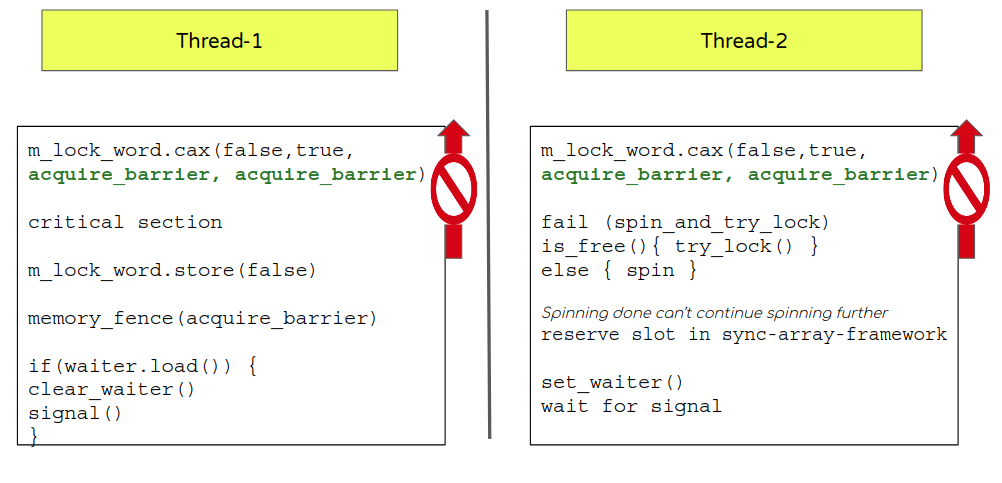
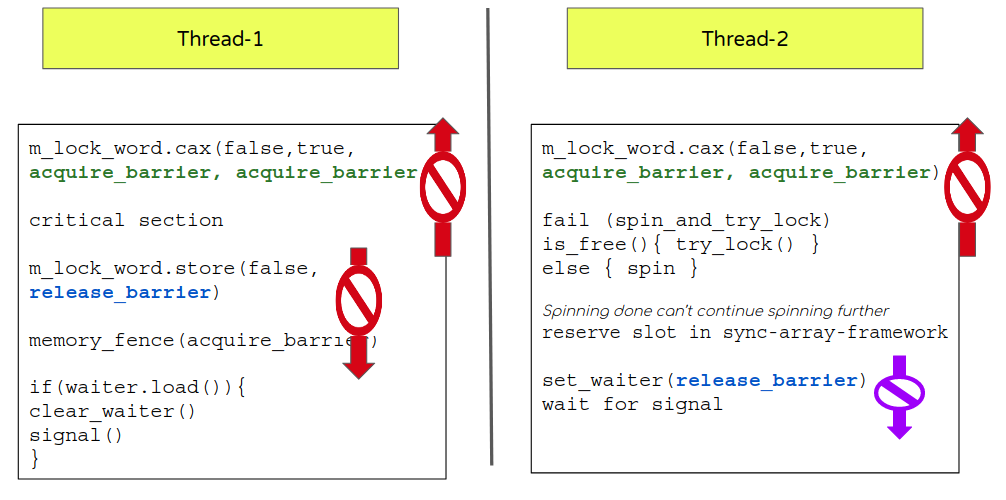
- From the above sequence it is pretty clear that while locking m_lock_word (false->true) it could potentially begin the critical section (if CAX succeeds) and so flow shouldn’t execute any statement from the critical section before the lock word is acquired (set to true).
- Going back to our acquire-release barrier section it suggests m_lock_word should take an acquire barrier incase of success (instead of default (seq_cst) as it currently does).
- But wait, there are 2 potential outcomes. What about failure? Even in case of failure, followup actions like spin, sleep and set-waiter should be done only post CAX evaluation. This again suggests use of an acquire barrier for failure case too. (instead of default (seq_cst) as it currently does).
- Now let’s look at the release barrier for m_lock_word. Naturally a release barrier will be placed once a critical section is done when the m_lock_word is toggled.
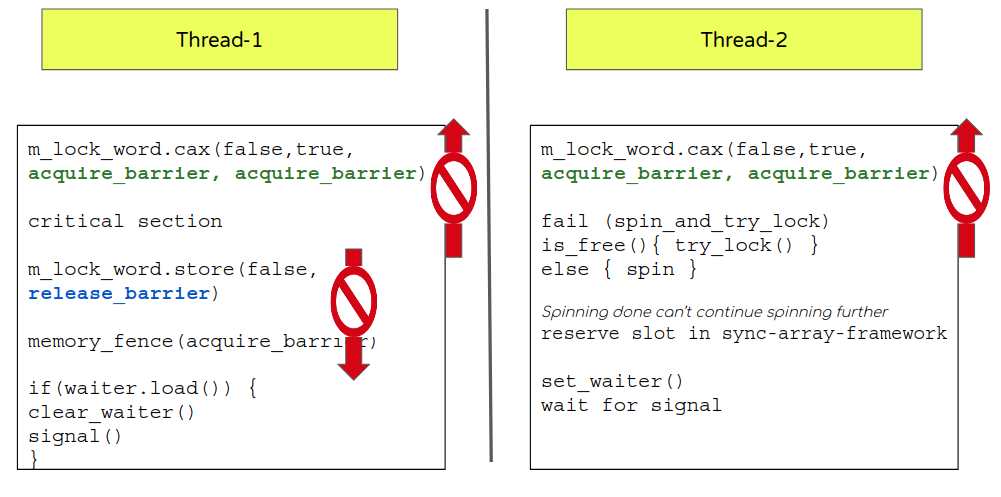
- There is another atomic variable (waiter flag) that needs to get a proper barrier too.
- Action to set a waiter flag should be done only when flow has ensured it can get a sync array slot. This naturally invites the need for a release barrier so the code is not re-ordered beyond set_waiter. Note: This is different atomic though so the co-ordination of m_lock_word acquire and release will not apply here.
-
Same way signal logic should be done only after the waiter flag is cleared so it should use an acquire barrier that will ensure it is not re-scheduled before the clear-waiter. (instead of release as it currently does).
-
This will also help us change the waiter-load flag check to use relaxed barrier (vs acquire). (There is a potential catch here; we will discuss it below).
-
With all that in place we should able to get rid of explicit memory_fence too.
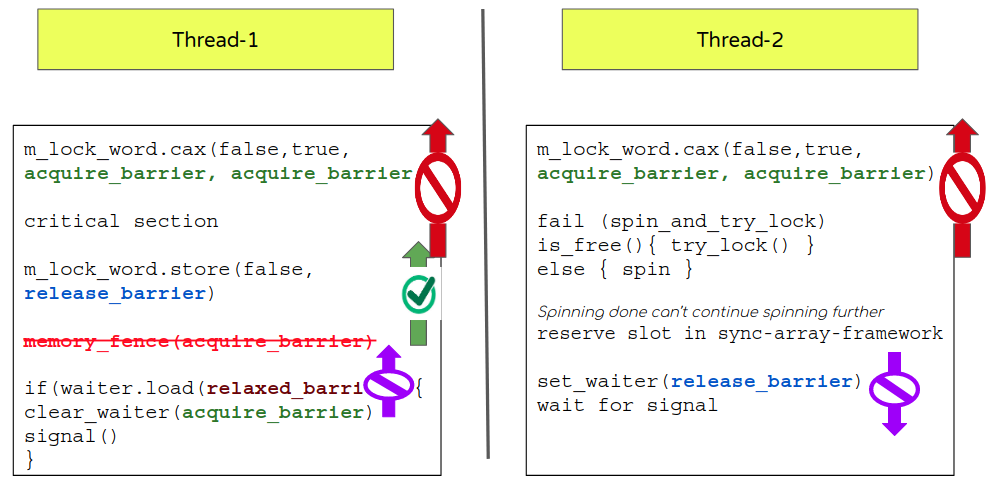
Anomalies:
- release-barrier on
lock_wordfollowed by an acquire-barrier onwaiterthis could be reordered.- This was even my understanding of potential risk and I presume that’s why MySQL introduced a fence between these 2 operations. As per the said blog, C++ standard should limit compilers from doing so.
- This was even my understanding of potential risk and I presume that’s why MySQL introduced a fence between these 2 operations. As per the said blog, C++ standard should limit compilers from doing so.
- By using a relaxed barrier for the waiter (while checking for its value) there is potential re-ordering that could move load instruction before the m_lock_word release (note: release barrier can allow followup instructions to get scheduled before it).
- If “waiter” is true then a signal loop will be called.
- If “waiter” is false then the signal loop will not be called by this thread but some other thread may call it.
- What if there are only 2 threads and thread-1 evaluates waiter=false by re-ordering it before the release barrier and then immediately posts that waiter is set to true by thread-2 and goes to wait. Now thread-1 will never signal thread-2.
So using a relaxed barrier is not possible so let’s switch it to use an acquire barrier that should avoid moving the followup statement beyond the said point and as clarified above release-acquire needs to follow C++ standard.
All this to help save an extra memory fence. memory-fence intention is to help co-ordinate non-atomic synchronization since our flow has inherent atomic (waiter) using proper memory barrier can help achieve the needed effect.
So with all that taken-care this is how things would look
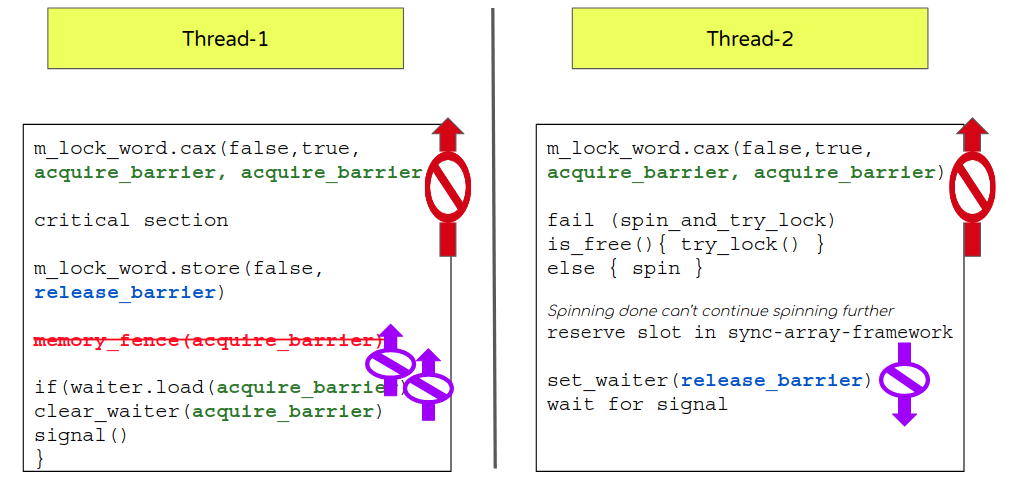
What we gained from this revamp?
So we achieved 3 things
-
Corrected use of memory barrier that helps also clarify the code/flow/developer intention. (This is one of the important thing stressed with use of memory barrier. Correct use will help make the code flow naturally obvious to understand and follow).
-
Moved from strict sequential ordering to one-way barrier without loosing on correctness. (acquire and release)
-
Avoided use of fence memory barrier meant for synchronization of non-atomic.
Revamp is not justified unless it has performance impact and this revamp is no exception. Revamp helps improve performance on ARM in range of 4-15% and on x86_64 in range of 4-6%.
Conclusion
Atomics are good but memory-barrier make them challanging and ensuring proper use of these barriers is key to the optimal performance on all platforms. Adaptation of barrier is catching up but still naive (though present in C+11) as most of the softwares recently started adapting to it. Proper use of barrier help clear the intention too.
If you have more questions/queries do let me know. Will try to answer them.