
Why run MySQL on ARM - Part 2
In the previous blog, we saw that users don’t lose anything by moving to MySQL on ARM. Infact, users are set to gain performance and save cost. In this blog post we will see performance numbers and analyze them to understand points where ARM scores.
Benchmarking Setup
Benchmarking is done using sysbench. We have used the CPM model. You can read more about it here. In short the idea is to keep the cost the same and hunt for comparable configuration.
- Server Configuration:
- sysbench 100 tables * 3 millions (roughly 69 GB of data)
- We tried 2 combinations:
- CPU Bound: buffer pool = 80 GB so complete data in memory (lesser IO).
- IO Bound: buffer pool = 35 GB so only 50% of the data (heavy IO).
- REDO-Log: 20 GB
- Server version: MySQL-8.0.21
- Test-Case scenarios:
- sysbench: point-select, read-only, read-write, update-index, update-non-index so all aspects are covered well.
- Access Pattern (please check sysbench site for exact details).
- Uniform: all data is touched with equal probability there-by generating more IO but lesser contention.
- Zipfian: part of the data is touched there-by generating lesser IO but more contention.
- Machine Configuration:
- x86_64: Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz (HT enabled) [28 ht-cores: 22 server + 6 client], 192GB mem
- ARM: Kunpeng 920 (2.6 Ghz) [64 cores: 56 server + 8 client], 192GB mem
- Storage:
- 1.6TB NVMe SSD (random read/write 180K/70K)
You can complete configuration here.
So keeping all other configuration (including cost) same computing power is allowed to vary. For the same cost we get 2.25x more cores of ARM.
Benchmarking Number
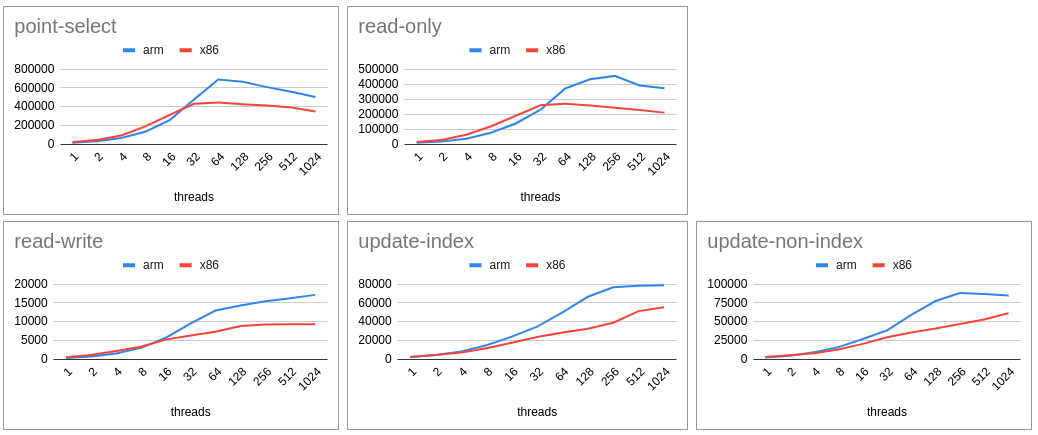
- Uniform - CPU Bound
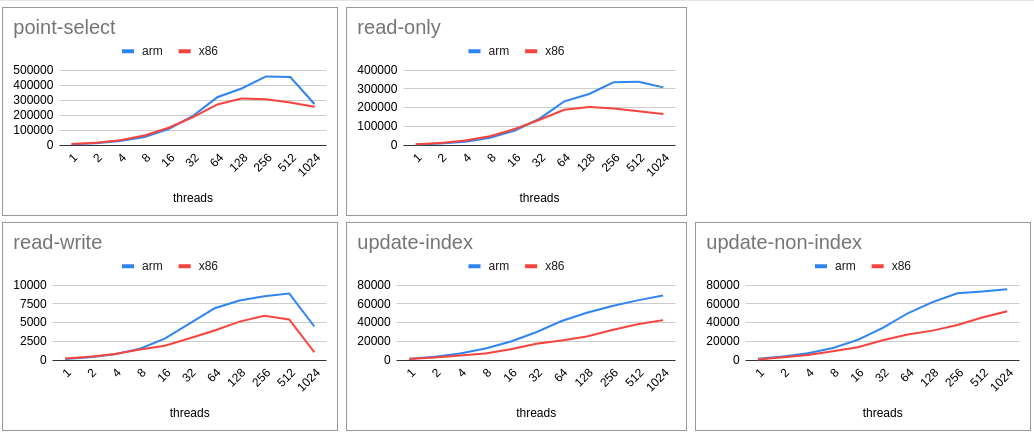
- Uniform - IO Bound
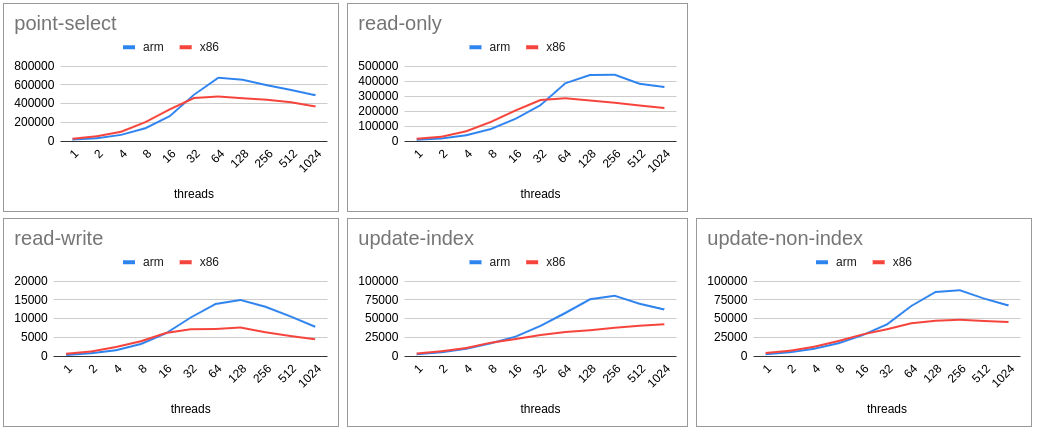
- Zipfian - CPU Bound
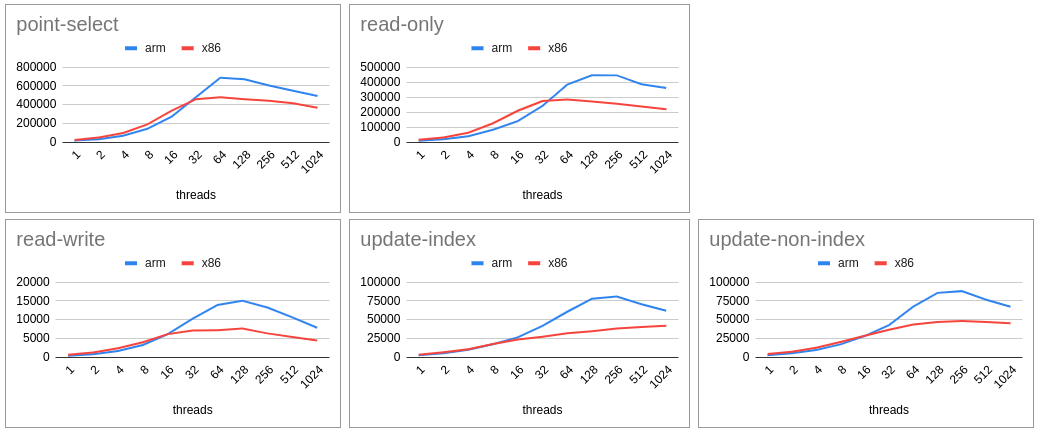
- Zipfian - IO Bound
Analysis
- MySQL on ARM continue to score with increasing scalability. Thanks to the extra computing power for the same cost.
- For lower scalability ARM is marginally lagging in some cases (mainly read-only).
- ARM continue to score consistently for all cases that includes with (zipfian) and without (uniform) contention and CPU (less IO) and IO (heavy flushing case).
- Difference for higher scalability is almost the double (in terms of tps/qps).
Let’s drill one level below and see what is causing the lag for lower-scalabiliy (in selected cases) and if this lag could be fixed or in general if the performance could be pushed further. We will use perf analysis.
Perf Profiling
-
Optimal Memory Barrier usage. ARM is a weak memory model but most of the code initially was optimized for x86 so defaulted to sequential consistency. ARM works well with sequential consistency too but for an optimal performance, switching to use an optimal memory barrier based on the new C++11 memory model would make it efficient for all architectures. Impact of this is widespread across the complete codebase and increasing with more atomics being used. Some of the top rated modules that will gain by switching to use optimal memory barriers are redo-log, performance-schema, undo-log, mdl locks, connection handling, etc…
-
Also, as part of defensive checks, explicit fences are added at some places. These are generally costly. Attempts are being made to get rid of some of these explicit fences. Switching to an optimal memory model would help get rid of most of these explicit fences.
-
rw-locks are still using traditional atomic methodology for atomic updates (vs C++11 atomic).
-
Branching model difference. Said branch may not get reported as a hot-spot on x86 but may get reported as a hot-spot on ARM. Branch prediction hints should help minimize this effect.
-
Need for a distributed counter to avoid cross-numa access (best to avoid even cross-core access).
-
CacheLine aligned global structure and counters to avoid cache line invalidation of unrelated variables.
-
Enabling 8 bytes optimal loops (like x86_64) for aarch64/arm64.
-
Use of software based checksum (crc32 and crc32c). InnoDB uses crc32c and for each page flush this is recalculated and quickly becomes top-5 costliest function.
Fortunately, lot of these issues have active community contributed patches available.
Besides this, there are other OS/Kernel level issues that hopefully will be fixed in upcoming series of kernel now that ARM is gaining wide popularity.
Conclusion
It is evident from the above experiment that switching to mysql on arm would turn to be beneficial from a cost and performance perspective. Also, with growing ecosystem and community support, performance of mysqlonarm will continue to scale further.
Happy #mysqlingonarm
If you have more questions/queries do let me know. Will try to answer them.