
Adaptive Purge in MariaDB
If you are using MariaDB for some time now you may have heard about adaptive flushing. “Adaptive” refers to a behavior where-in the algorithm auto-tunes itself based on certain parameters. In the new-generation world, it is called an “AI-based algorithm”. The same concept is now being applied to purge. Purge is a critical and resource-consuming operation so scheduling of purge along with user workload needs to be balanced. This is what exactly adaptive purge would do.
A quick note on purge
MySQL/MariaDB doesn’t immediately delete the data. Data is marked for delete and updated data is placed in the mainline tree. Old data is copied over to UNDO logs. This is needed to support multi-version concurrency control (further details are beyond the scope of this blog so you can always read details here).
These old copies needs to be cleaned/removed/purged once there is no active transactions referring to it. This is done by the purge operations in the background. There are dedicated purge thread(s) meant to do this operation. Configurable using innodb_purge_threads (default=4/max=32).
If purge is being done aggressively along with the active user workload, the latter will start seeing effects like jitter, reduced performance, etc.. Let’s see how adaptive purge could help solve these issues.
Benchmarking purge with user workload
- MariaDB-Server:
- MariaDB Server 10.6.4 (GA; without adaptive purge)
- MariaDB Server 10.6.5 (trunk work-in-progress; with adaptive purge folded)
- Machine Configuration:
- ARM: 24 vCPU (2 NUMA) ARM Kunpeng 920 CPU @ 2.6 Ghz
- X86: 24 vCPU (2 NUMA) Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz
- Disk: read/write 350 MB/sec
- Workload :
- sysbench: test: oltp-update-index, scalability: 128, pattern: uniform
- 5 rounds 300 seconds each is executed with a 20-sec gap between each round.
- In parallel, history length is tracked.
- Server configuration: here (+ innodb_purge_threads=4 (default)).
- Data: 35GB
Benchmark (without adaptive purge):
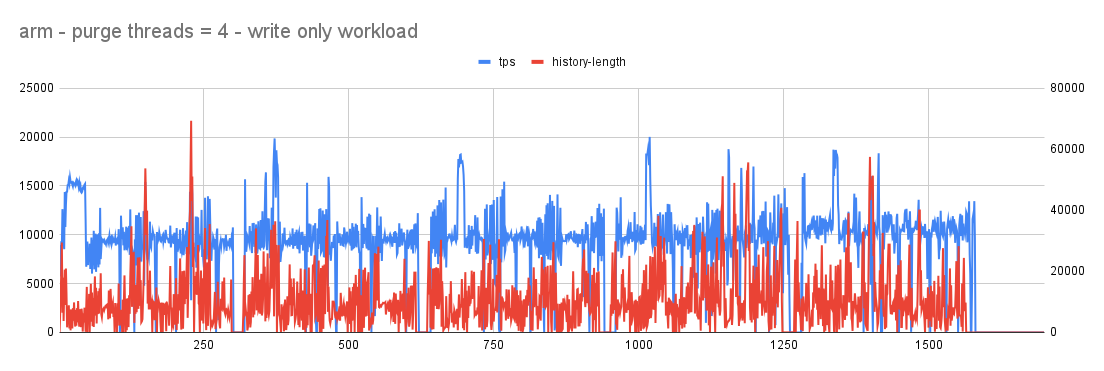
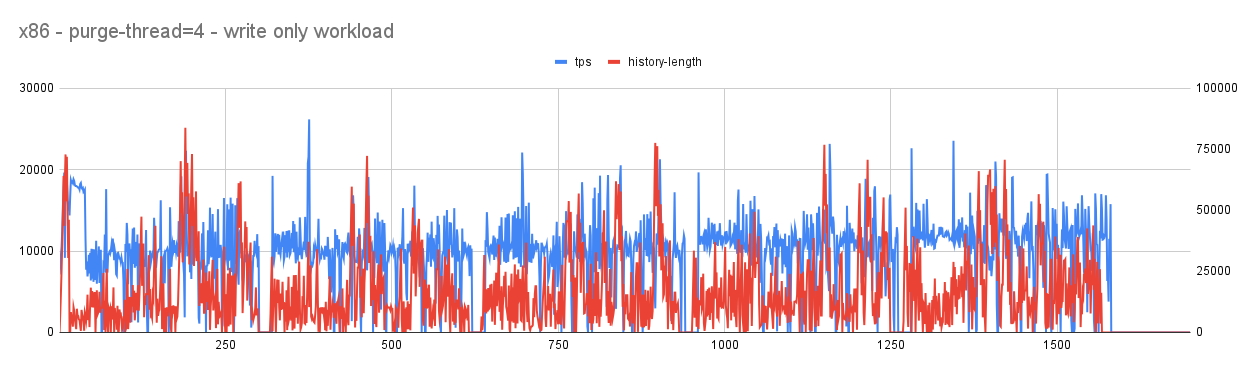
With purge-threads=4
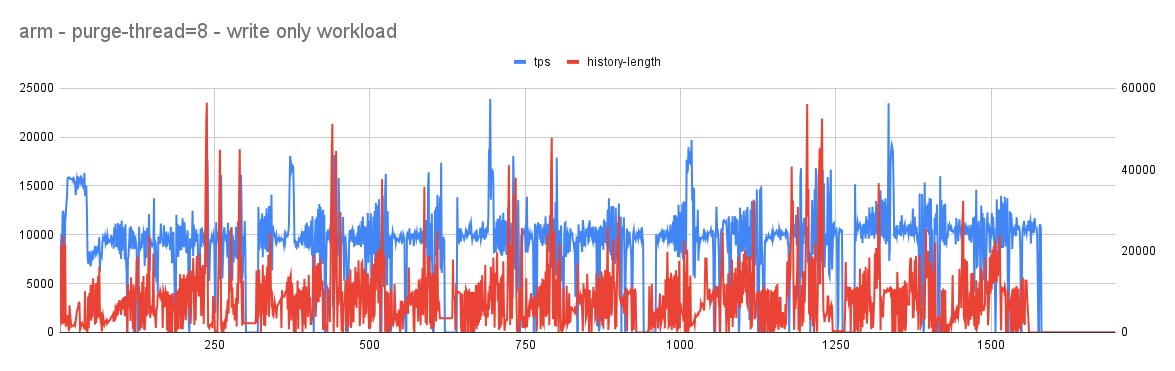
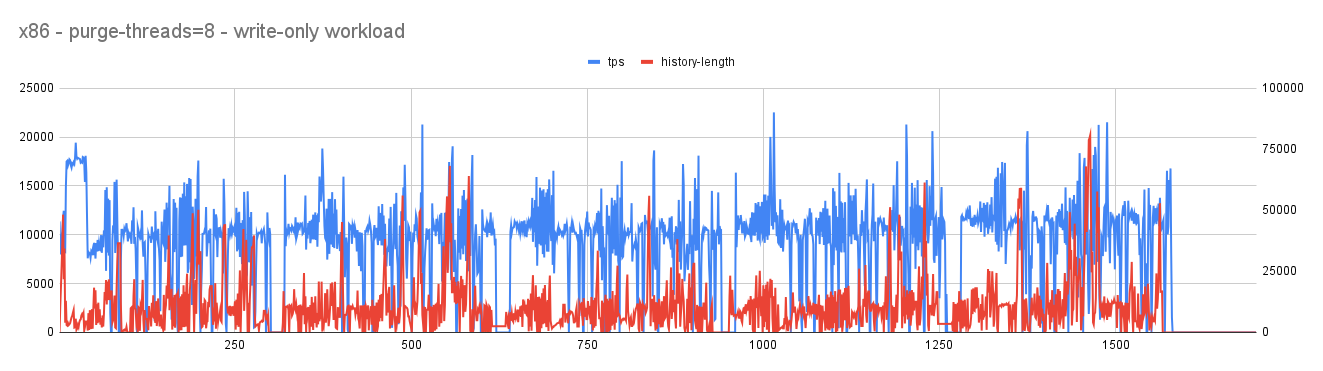
With purge-threads=8
Observations
- In both cases (arm and x86) user workloads continues to show a lot of jitters with tps occasionally touching 0. history-length is kept in check that suggests an aggressive purge is taking place.
- Given the workload is user-workload the jitter with tps touching 0 is least expected and that needs to be improved. Investigative analysis showed that aggressive background purge continues to generate a lot of redo that puts pressure on redo log filling it fast and once the threshold is crossed furious flushing starts causing jitter with user workload.
- Here an important decision needs to be made. If we have limited resources, active workload (like user workload) needs to get priority in using it and passive workload (like purge) could be delayed or throttled to a level so that the mainline performance is not affected.
Adaptive Purge (part of MariaDB-10.6.5)
The purge system is multi-threaded with N threads progressing in parallel. If we can limit these threads (based on the redo log fill factor) we can limit the pressure, purge is adding on the redo-log allowing the user/active workload to make effective use of redo-log. On the flip side, there will be an increase in history length and in turn larger undo-logs (that can eventually truncate with mariadb supporting undo log truncate).
Let’s try to devise an algorithm using this rule and see if that helps improve active workload.
- Phase-1:
- adaptive purge continues to monitor the redo-log size. If the redo-log-size < lower watermark nothing is done.
- Phase-2:
- Once the redo log size crosses the lower watermark, the adaptive purge will kick in.
- As part of the logic, the range between lower and higher watermark is divided into N buckets (N = innodb_purge_threads). As and when redo log continues to cross the bucket, purge threads continue to reduce/increase by 1.
- Say, innodb_purge_threads=4. This will create 4 buckets. When the redo log is within the range of 1st bucket then the purge system will operate with 4 purge threads. When the redo log grows and enters the range of the 2nd bucket, the purge system will operate with 3 purge threads and so on. With increasing redo-log size, purge is throttled and with reducing size aggressive purge is re-enabled.
- Phase-3:
- Once the redo-log crosses the higher watermark (by then purge system is already operating with 1 purge thread) an additional delay of 10 ms is introduced to avoid scheduling purge back to back.
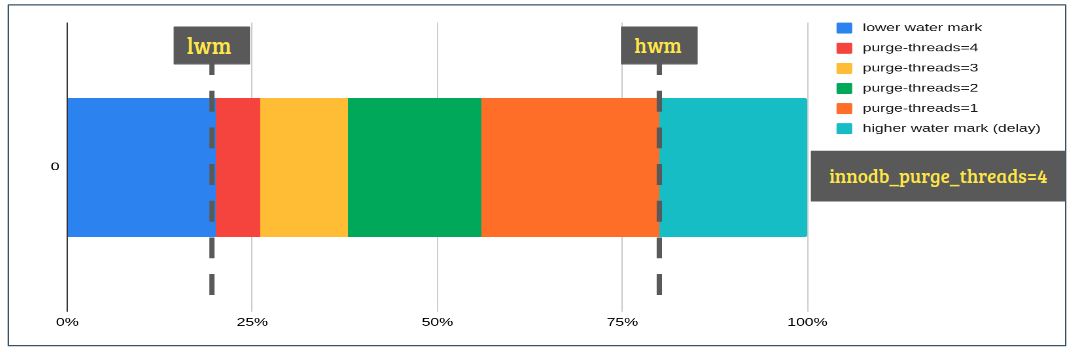
Note: lower and higher watermarks are pre-configured to 20/80 (currently not user-configurable. not sure if really needed). The number of buckets/ranges depends upon the number of purge threads. The ranges are created using arithmetic progression if possible otherwise, an average distribution is used.
Benchmark (with adaptive purge):
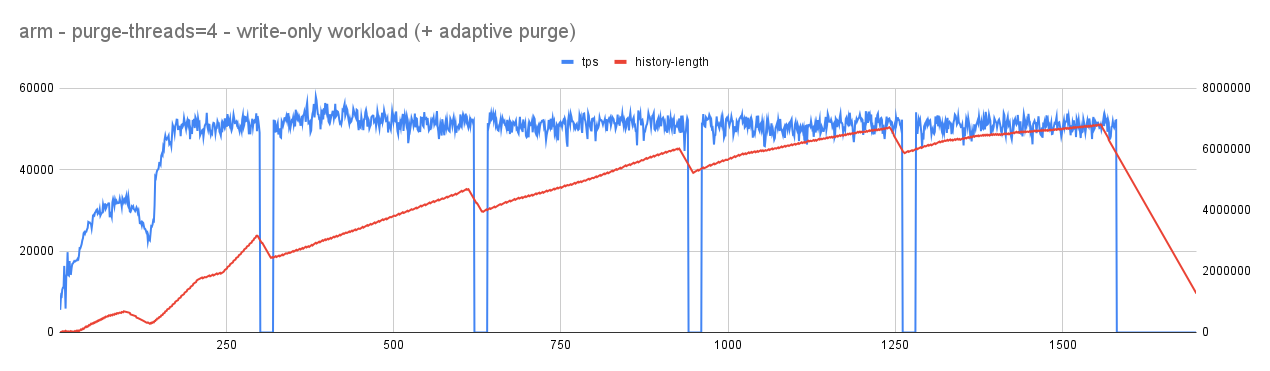
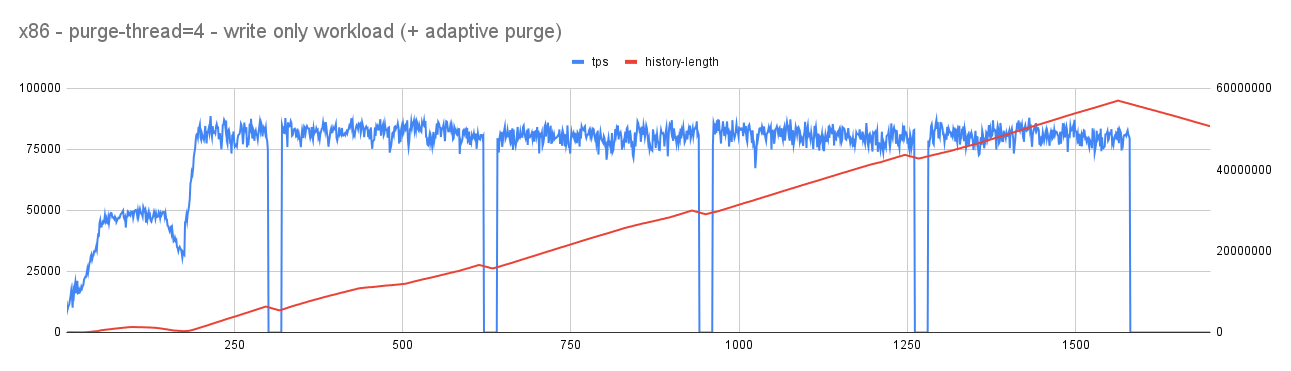
With purge-threads=4
With purge-threads=8
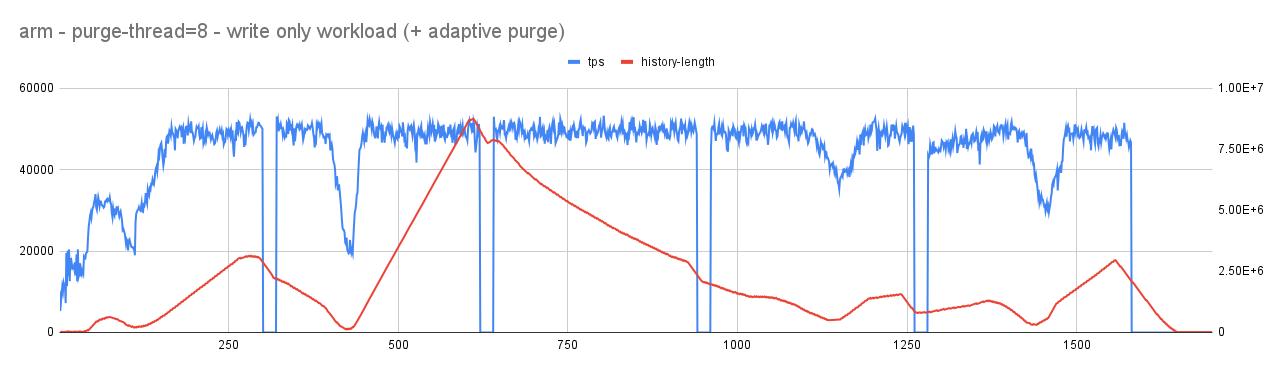
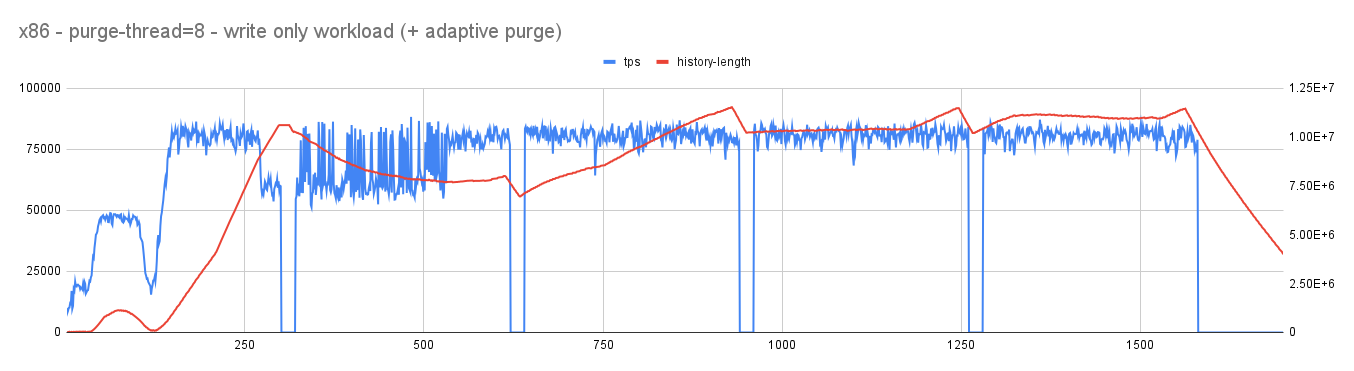
Observations
- As expected, with reduced pressure on redo log, jitter in user/active workload considerably reduced. Importantly, overall throughput improved from an average of 10K tps to 55K tps (ARM). This improvement is due to reduced pressure on log_sys mutex (related to redo-log).
- As a flip-side, history length increases but when there is an idle time it continues to fall steeply allowing it to reach considerable range without affecting the mainline performance.
- Also, with changing redo-log ranges, the purge system continues to become aggressive (purge threads increasing) or conservative (purge thread decreasing).
Caveats
-
If your workload and/or configuration are such that even without purge the active workload continues to put pressure on redo-log, in such cases furious flushing will take place but this algorithm will not solve the said issue since it is not originating from the purge.
-
With the faster disk (say NVMe SSD), we observed that flushing is done quite fast thereby keeping a check on redo-log size and so adaptive purge may not kick in (depending on size of redo-log).
Conclusion
Adaptive purge not only helps reduce jitter in performance but also helps improve overall throughput there-by improving the responsiveness of the server (including latency).
If you have more questions/queries do let me know. Will try to answer them.