
GCC vs Clang - with MariaDB on ARM
It is a well-known fact that a good compiler can emit an optimal code thereby allowing software to produce better throughput. Clang compiler popularity continues to grow and since I am working mostly on performance issues I am often asked if I have tried MariaDB-on-Arm with clang compiled binaries. Finally, I got some time and decided to try it out.
Setup
- ARM instance: 24 vCPU Kunpeng 920 (2.6 Ghz), 48 GB of memory
- MariaDB-Server: 10.6 trunk (#76972163)
- Compiler:
- clang-11.1
- gcc-10.1
- Was also checking the ARM C/C++ compiler but seems like there is licensed version only (please let me knows if there is a free-to-use for opensource community license available).
- OS: Ubuntu 18.04
- Workload: sysbench point-select, read-only, update-index, update-non-index. CPU bound, pattern=uniform(uni)/zipfian(zip).
- Scalability: 128, 256 (+ 512) threads
- optimization flags: default (O2), O3, Ofast
Benchmarking
read-only workload
The difference is quite marginal in most cases so a normal graph will not be able to capture it clearly so we will use some kind of heat map.
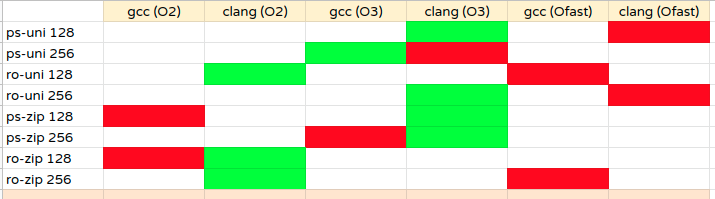 Notes: green cell represents the highest throughput for the said test case. Like for ps-uni (point-select uniform 128 threads), the highest throughput is seen with clang-o3 and lowest with clang-ofast
Notes: green cell represents the highest throughput for the said test case. Like for ps-uni (point-select uniform 128 threads), the highest throughput is seen with clang-o3 and lowest with clang-ofast
Observations
- In most cases, clang O2/O3 has performed better than gcc.
- Ofast fails to perform for both gcc or clang.
- default (gcc-O2) tend to perform worse/average for most cases. (For no scenario, it is able to perform best).
read-write workload
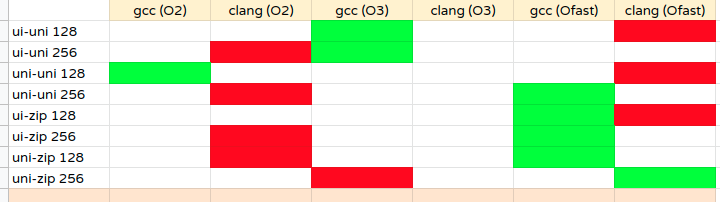
Observations
- For read-write workload, the picture is quite different. clang-O2 continues to perform worse. clang-O3 average and clang-Ofast fill the missing lower throughput gaps left by clang-O2. In short, clang continues to perform worse for the read-write workload.
- On other hand, gcc continue to score well for read-write workload with O3 and Ofast giving the best performance.
- It is interesting to note that only for update-non-index (zipfian) 256 use-case, clang-Ofast score quite well.
increasing scalability/contention further
Based on overall observation it sounds like with a lot of contention and higher throughput clang continues to perform but with normal contention and lower throughput gcc continues to perform. Let’s try to re-confirm this with some more experiments.
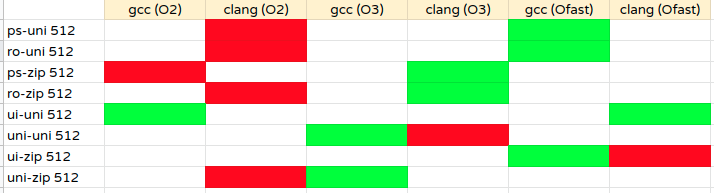
Observations
- Again, we continue to see mixed results but with increasing scalability it sounds like gcc with -Ofast tends to score.
- If we try to consider all the 3 heat-maps and try to score them (-1 for red count and +1 for green count) and add it columnwise then clang -O3 and gcc -Ofast seems to be on-par.
Let’s try to run a full benchmark with all thread scalabilities (1-256) with the short-listed modes (gcc-Ofast, clang-O3)
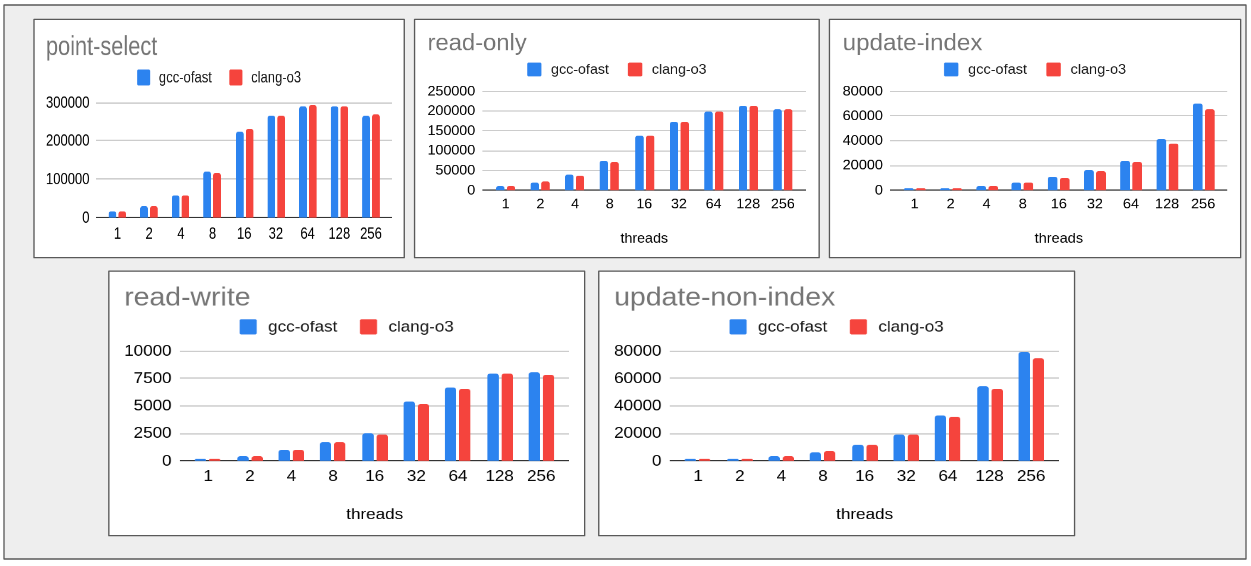
- As we could see for read-only workload clang-O3 continue to score marginally but with read-write workload gcc Ofast continue to score with some visible differences.
Conclusion
Based on the said study, there is no clear winner. Depending on use-case at times clang score and at times gcc score. Of-course the optimization mode could be O3 with clang and Ofast with gcc. Also, make a note that -Ofast (optimize very aggressively to the point of breaking standard compliance).
If you have more questions/queries do let me know. Will try to answer them.