
Understanding NUMA scalability with MariaDB 10.6
Increasing cores means more compute power but it is quite likely that this power is distributed across more numa nodes. Also, traditional arrangement where-in 1 cpu socket = 1 numa node too is changing. Already we have arrangements where-in cores from a single cpu socket are organized to form 2 numa nodes. Next generation softwares (including DB) needs to adapt to these changing arrangements to scale well on such multi-numa machines.
NUMA Scalability
Most of the software hits compute or IO contention and it could be relaxed by providing more resources. This is traditionally referred to as SCALABILITY BOTTLENECK. What if we say that increasing compute power fails to scale software. It is a common problem if the software is not NUMA aware.
Fortunately, MariaDB through its continuous development has already adapted to this changing NUMA arrangement and is continuously getting better. Still there are scenarios that need to be addressed. Let’s try to understand some of these NUMA scalability issues.
Setup
- Machine Configuration:
- ARM: 128 cores (4 NUMA, 2 CPU Sockets) ARM Kunpeng 920 CPU @ 2.6 Ghz
- X86: 72 cores (2 NUMA, 2 CPU sockets) Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz
- Workload (using sysbench):
- CPU bound (around 80 GB of data)
- Pattern: uniform, zipfian
- Scalability: 1/2/4 numa. 512/1024 threads for each NUMA.
- Other configuration details here (+ skip-log-bin).
- Storage: NvME SSD.
- MariaDB Version: 10.6.2 (tagged RC)
read-only workload
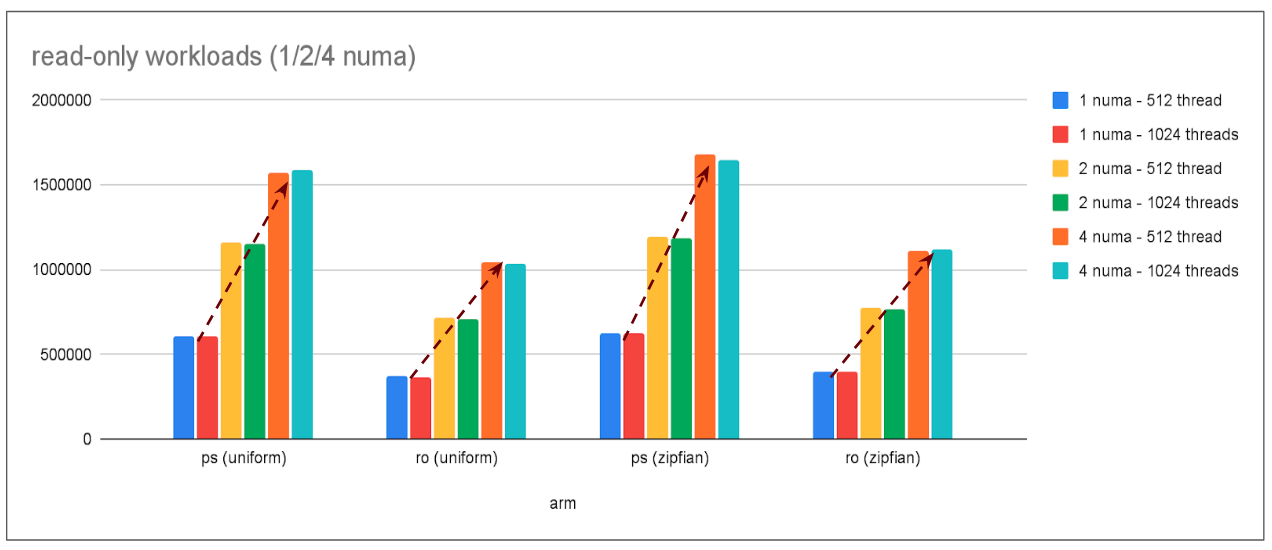 Note: ps: point-select, ro: read-only
Note: ps: point-select, ro: read-only
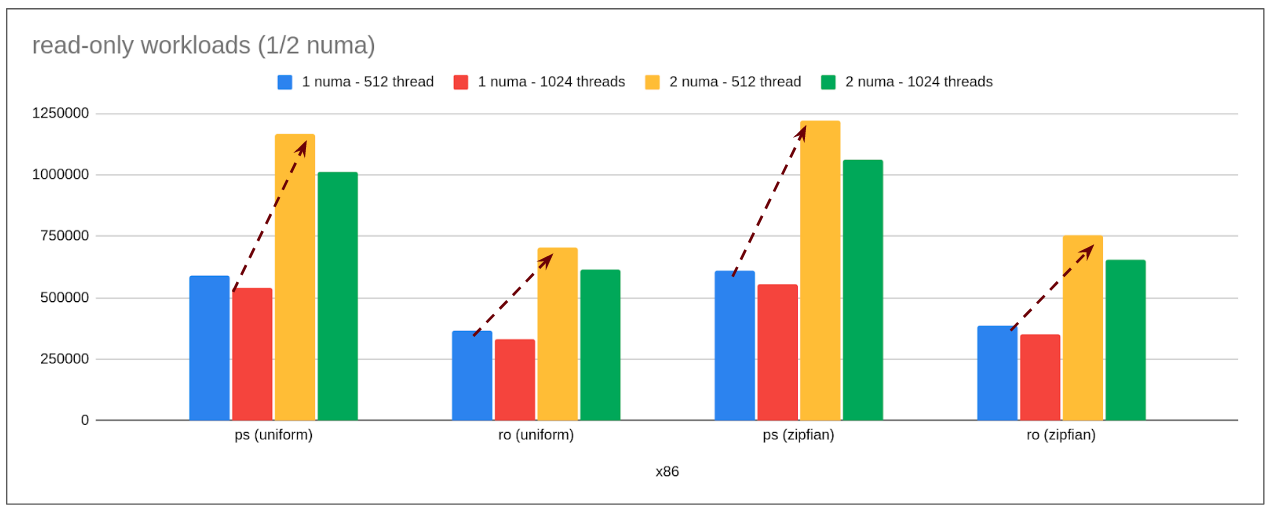 Note: ps: point-select, ro: read-only
Note: ps: point-select, ro: read-only
- Observation:
- With increasing compute power (in turn increasing numa nodes), performance continues to scale linearly (with cross-numa latency overhead inline with what OS reports).
On side note: If we carefully observe then there is a drop in performance from 512->1024 threads; this is a scalability bottleneck seen for all numa node configurations.
read-write workload
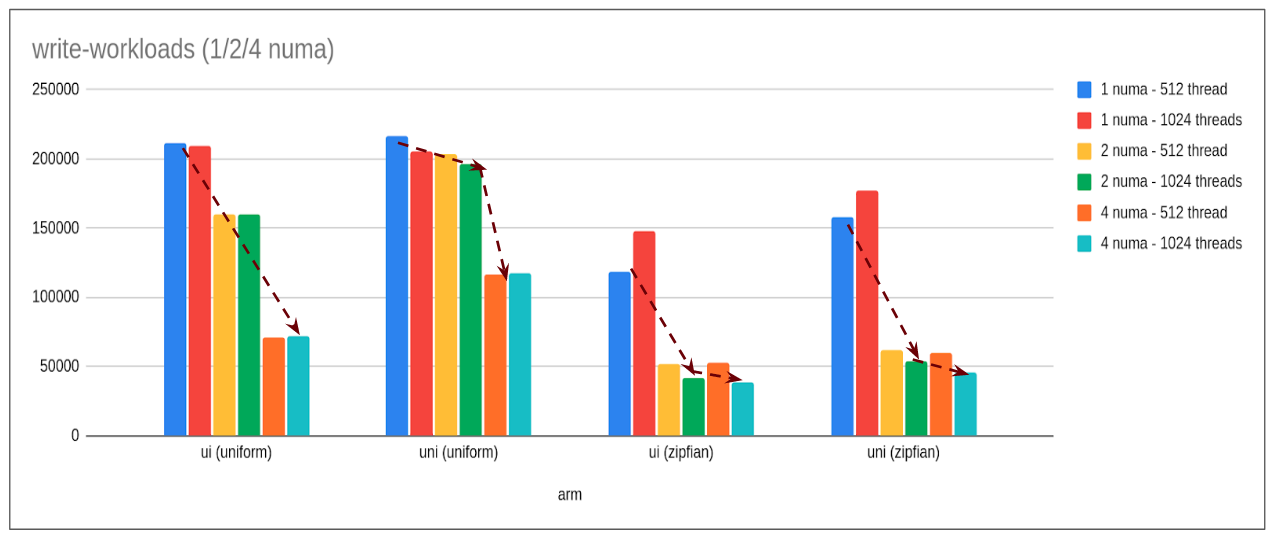 Note: ui: update-index, uni: update-non-index
Note: ui: update-index, uni: update-non-index
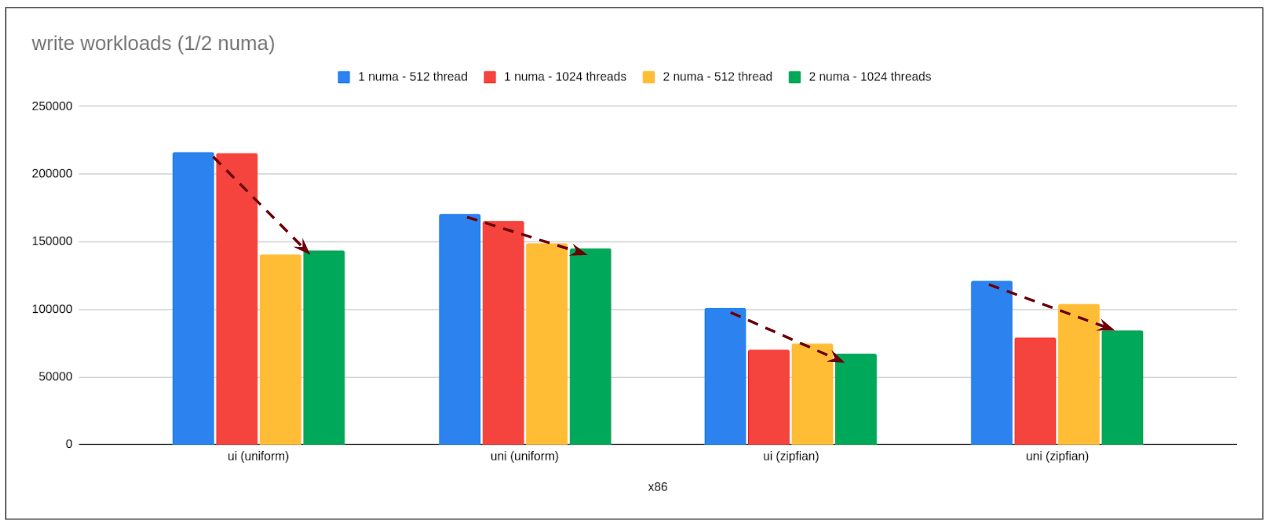 Note: ui: update-index, uni: update-non-index
Note: ui: update-index, uni: update-non-index
- Observation:
- Here the pattern is exactly opposite. Instead of linearly scaling it is linearly regressing with increasing numa nodes.
Analysis
This naturally prompted us to look at the possible cause and as expected (at-least, for some of the readers) it turned out that log-sys and redo log mutex are the main culprits.
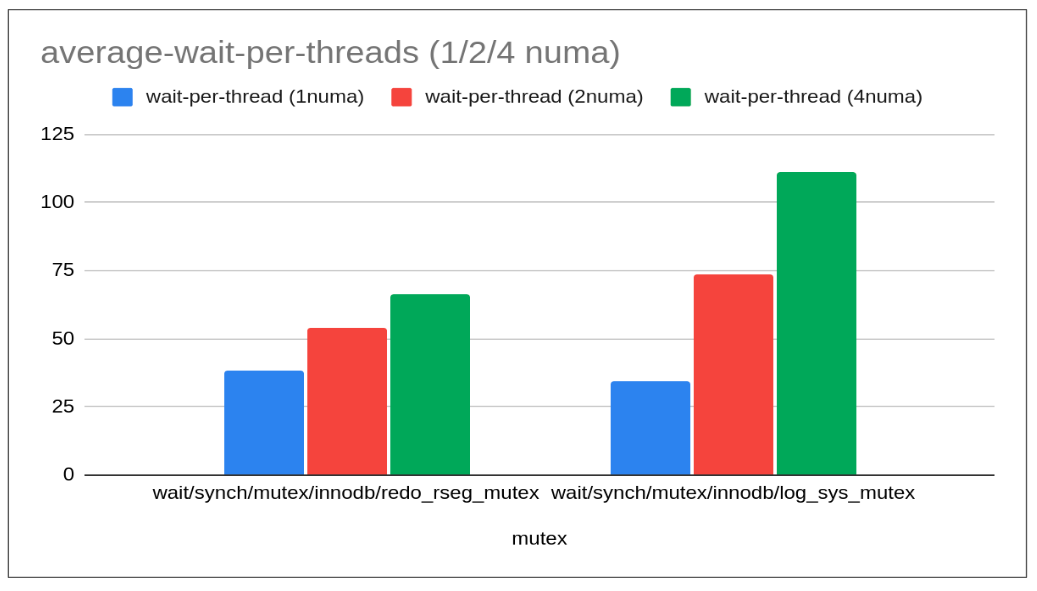 time in seconds. Average wait per thread calculated for 512 threads. zipfian workload
time in seconds. Average wait per thread calculated for 512 threads. zipfian workload
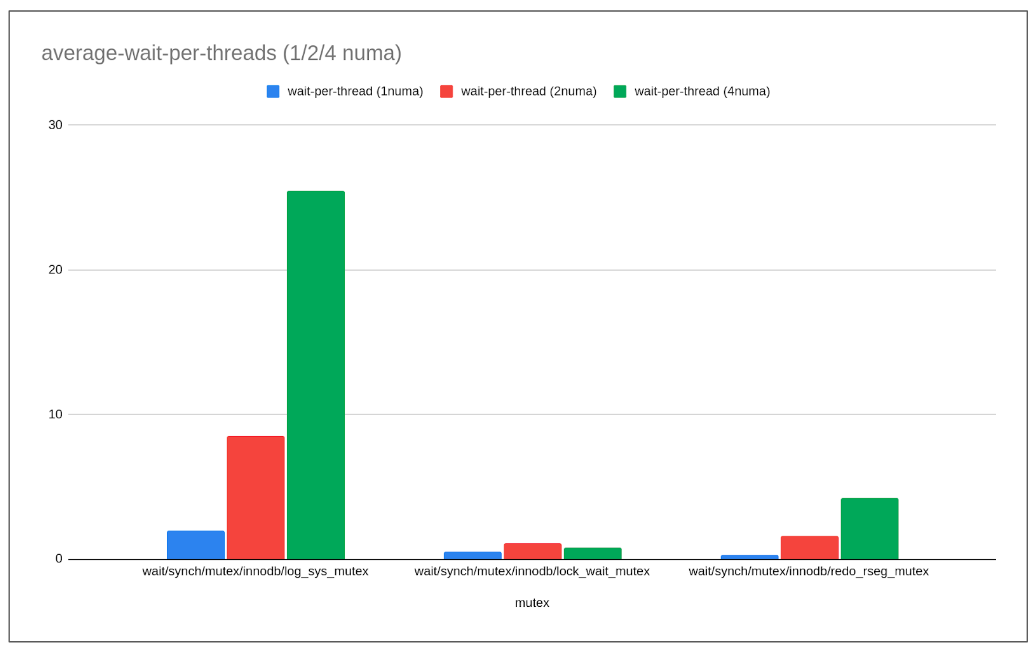 time in seconds. Average wait per thread calculated for 512 threads. zipfian workload
time in seconds. Average wait per thread calculated for 512 threads. zipfian workload
- So with increasing numa nodes we see log-sys mutex and redo-rseg mutex fail to scale there-by linear increase in the wait time per thread which runs upto into ‘00 of seconds causing overall slowness.
- Most of the other followup mutexes have pretty less wait time for now. Once the contention of these 2 main mutexes is resolved other followup mutexes may show-up and another round of optimization could be needed. (Interestingly, mysql has resolved both of these contentions but mysql hits trx_sys contention which MariaDB has resolved).
Good part is both of these issues are actively being tracked and the MariaDB team is actively working on it. So eventually we can expect a better NUMA scalability even for read-write workload.
Conclusion
So next time you start evaluating scenarios do check for NUMA configuration and depending on your use-case/workload and version you are using you could get better throughput even with lesser cores.
If you have more questions/queries do let me know. Will try to answer them.