
Benchmarking MariaDB on ARM with TPCC
Majority of the users use cases are covered with sysbench variants of workload but there are users who have use-cases that could be best represented with TPCC or for that matter they would like to compare 2 databases using TPCC as a base standard. To help fill this gap I decided to evaluate TPCC using MariaDB on ARM.
Setup
- Machine Configuration:
- ARM: 128 vCPU (4 NUMA) ARM Kunpeng 920 CPU @ 2.6 Ghz
- x86: 64 vCPU (2 NUMA) Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz
- Workload (TPCC using sysbench) : –tables=10 –scale=100
- https://github.com/Percona-Lab/sysbench-tpcc
- Other configuration details here (+ thread_handling=pool-of-threads).
- Shared Buffer: 120GB
- Data: 95 GB
- Redo-Log: 30 GB
- Storage: NVME SSD
- sequential read/write IOPS: 190+K/125+K
- random read/write IOPS: 180+K/65+K
- MariaDB Version:
- 10.8.3 (work-in-progress. Wanted to use redo-log optimization).
- Scalability: 1-1024 threads
Benchmarking
- For ARM, we benchmarked TPCC with 4 different (1/2/4) NUMA configurations.
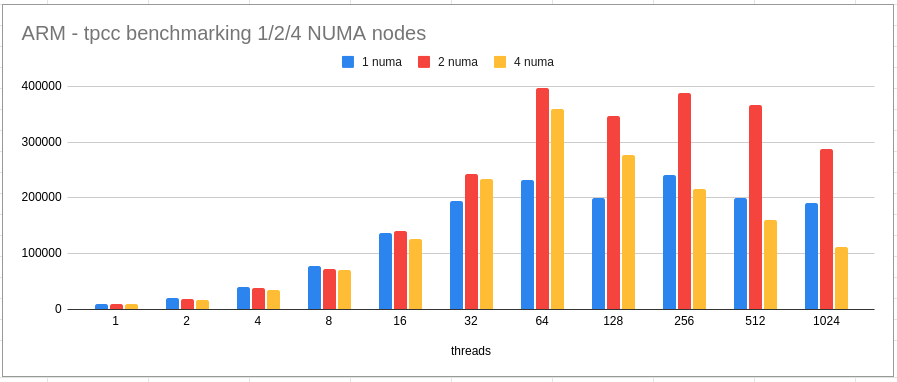
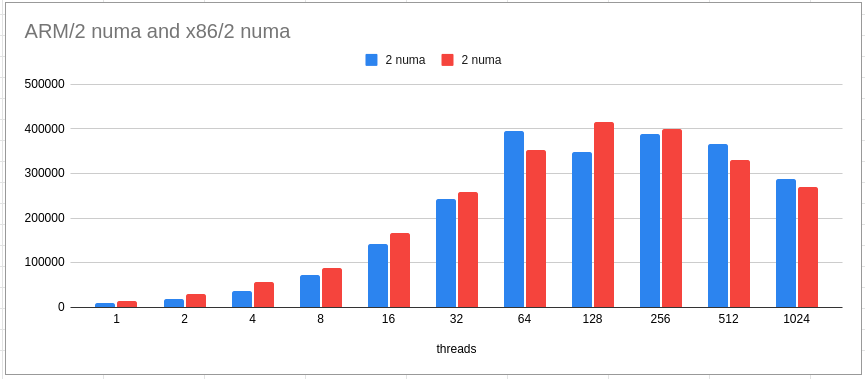
- We also compared 2 NUMA ARM and 2 NUMA x86 configurations to check if the ARM is performing on par with what the user would expect or used to. Both configurations have the same number of vCPU with different frequencies (2.6 (arm) vs 3 (x86)).
Observations:
- MariaDB on ARM continues to perform in line with the expectation even with TPCC workload.
- MariaDB on ARM continues to be on par or even beat x86 performance, especially with higher scalability (despite of difference in frequency and ~50% lesser TCO).
- For higher scalability, with 4 NUMA nodes, throughput continue to drop well below 50% (with respect to 2 NUMA node). Let’s quickly understand what is causing it.
perf profiling with 2 NUMA
+ 17.66% 12557 mysqld [kernel.kallsyms] [k] queued_spin_lock_slowpath
+ 8.70% 6544 mysqld mariadbd [.] l_find
+ 5.56% 78524 mysqld [kernel.kallsyms] [k] finish_task_switch
+ 3.34% 2887 mysqld mariadbd [.] MYSQLparse
+ 2.89% 2090 mysqld mariadbd [.] rec_get_offsets_func
+ 2.55% 1899 mysqld [kernel.kallsyms] [k] __wake_up_common_lock
| wait/synch/rwlock/innodb/lock_latch | 1497129.9573 | 73915212 |
| wait/synch/rwlock/innodb/log_latch | 802585.5836 | 79094893 |
| wait/synch/cond/mysys/COND_timer | 217272.8043 | 786 |
| wait/synch/cond/threadpool/timer_cond | 216049.2886 | 432 |
| wait/synch/cond/aria/SERVICE_THREAD_CONTROL::COND_control | 209020.7979 | 7 |
| wait/synch/sxlock/innodb/index_tree_rw_lock | 118856.8702 | 118740596 |
perf profiling with 4 NUMA
+ 58.35% 31357 mysqld [kernel.kallsyms] [k] queued_spin_lock_slowpath
+ 3.40% 1883 mysqld mariadbd [.] l_find
+ 1.62% 146440 mysqld [kernel.kallsyms] [k] finish_task_switch
+ 1.46% 1062 mysqld mariadbd [.] rec_get_offsets_func
+ 1.45% 883 mysqld mariadbd [.] buf_page_get_low
| wait/synch/sxlock/innodb/index_tree_rw_lock | 6927204.8781 | 52455490 |
| wait/synch/rwlock/innodb/lock_latch | 6760422.3653 | 28812428 |
| wait/synch/rwlock/innodb/log_latch | 2650246.1917 | 32740980 |
| wait/synch/rwlock/sql/MDL_lock::rwlock | 221800.4496 | 40688789 |
| wait/synch/cond/mysys/COND_timer | 188957.6817 | 673 |
Contention for lock_latch (in previous versions lock_sys.mutex) and log_latch (in previous version log_sys.mutex) has increased (inline with expectation as revealed with sysbench workloads too) but it is suprising to see index_tree_rw_lock contention increasing with 4 NUMA nodes. This contention now occupies top slot and has grown multi-fold from 6th to 1st position. Surely it deemed for the further investigation cum optimization. (I tried some quick approaches like cacheline and spin-mutex. Nothing helped. Need to look at the access pattern).
Conclusion
TPCC workload scale quite well with MariaDB on ARM. Growing NUMA nodes continue to pose challenges but those could be addressed as part of the wider/generic optimization. Sysbench access workload mostly shows up log_sys and lock contention but with TPCC we started seeing a different contention too.
If you have more questions/queries do let me know. Will try to answer them.