
Tune your MariaDB IO workload using this simple step
Tuning IO workloads is often challenging given it involves optimal usage of available IO bandwidth. MariaDB has multiple options to control this but often users tend to ignore the simpler options and tend to play around with complex or wrong options. In this article, we will take a step-by-step approach and see if we can tune an IO workload.
A quick note about flushing
Before we get into details let’s first refresh our understanding of the flushing in MariaDB as it exists today (10.6.3 GA).
- During boot time all the pages are added to the free list.
- Workload then starts demanding the page. If the page is not present then the page is allocated from the free list and moved into the LRU list followed by IO from disk to the allocated page.
- If workload happens to change the page then said page is added to flush list that is sorted based on changes done (lsn).
- The page-cleaner thread continues to flush the page to disk at regular intervals as per the configured parameters. This ensures that checkpoint age is kept under the threshold to avoid furious flushing. Flushed pages are marked clean (not freed). They continue to hold the data and workload can pin them for further use (without need for IO). This also means flushing doesn’t increase the free-page list length.
- Whenever workload needs a page it tries to get it from a free list. If the free list is exhausted LRU algorithm kicks in. A page is selected for replacement. If the said page is clean then it could be used immediately (without the need for IO) else the page first needs to be flushed to the disk. This is termed as LRU flush and different from the normal flush (note: normal flush doesn’t generate free page but LRU flush will generate free page).
- Now the LRU flush algorithm has an option to flush a page whenever needed or flush in batches (like N pages) at times. Also, it is quite possible that out of these N pages, some are already clean so there is no IO overhead to replace such pages (only evict and reload the new page).
With that basic understanding let’s now see if we can tune the IO workload.
Setup
- Machine Configuration:
- ARM: 64 vCPU (2 NUMA) ARM Kunpeng 920 CPU @ 2.6 Ghz
- X86: 64 vCPU (2 NUMA) Intel(R) Xeon(R) Gold 6151 CPU @ 3.00GHz
- Workload (using sysbench):
- IO-bound (only 50% of the data in buffer pool)
- Pattern: uniform
- Other configuration details here (+ skip-log-bin).
- Buffer Pool: 35GB
- Data: 70GB
- Redo-log: 20 GB
- Storage: NvME SSD (for both machines)
- sequential read/write IOPS: 190+K/125+K
- random read/write IOPS: 180+K/65+K
- MariaDB Version: 10.6.3 (tagged GA)
- Scalability: 512 threads
Iteration-1
- Given IO involved, the most obvious setting that the majority of the user tends to tune is
innodb_io_capacityandinnodb_io_capacity_max. A general recommendation suggests setting these values to something lower like 1K/2K for a high-speed disk to avoid writing a copy of the page multiple times there-by making old copies stale in no time and in turn reducing the SSD endurance. - The flip side of these really low values is clearly visible on performance.
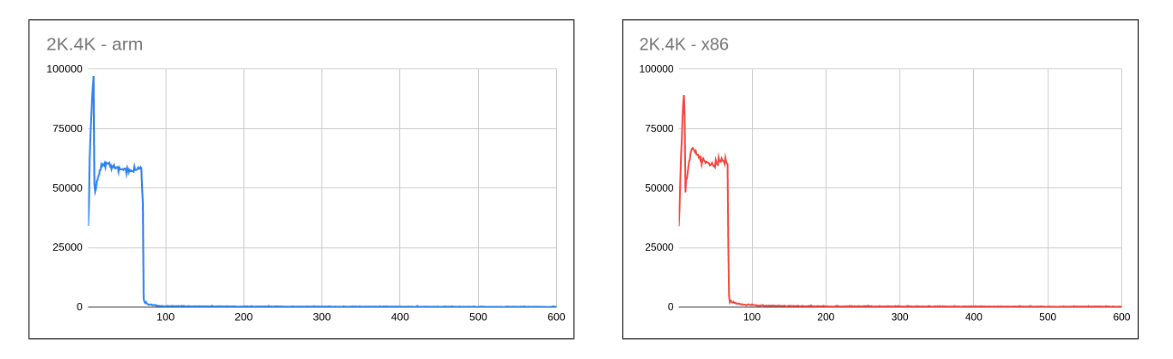
- Once the adaptive flushing kicks it is unable to keepup with the rate at which pages are being modified causing performance to drop close to 0 (actual values are around 100-500 range) as dirty pages hit the threshold.
Iteration-2
- Learning from experience we now decided to increase the innodb_io_capacity/innodb_io_capacity_max to 12K/24K. Why 12K? We have to start somewhere and some of the common cloud volumes offer speed in the range of 250-350 MB/sec that is around 16K-22K.
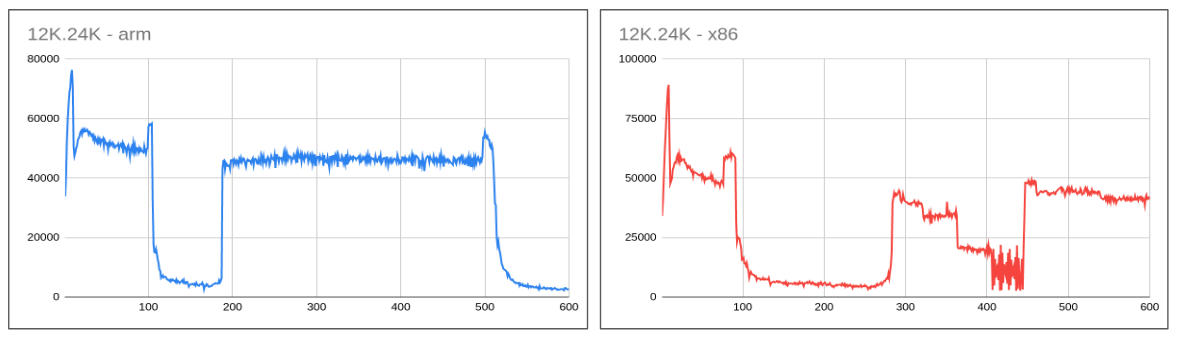
- There is an improvement but still, the performance is not consistent. In fact, for a production user, a system like this is more dangerous due to a wide range of performance fluctuations. The drop in the above case is coming from dirty page hitting threshold (innodb_max_dirty_pages_pct=90).
Iteration-3
- Given we have a really fast disk let’s allocate the maximum possible capacity. Please make a note that innodb_io_capacity represents IOPS which includes read and write operations and some of them could be sequential too. Given this fact, we set innodb_io_capacity/innodb_io_capacity_max to 120K/120K allowing adaptive flushing to figure out best possible usage.
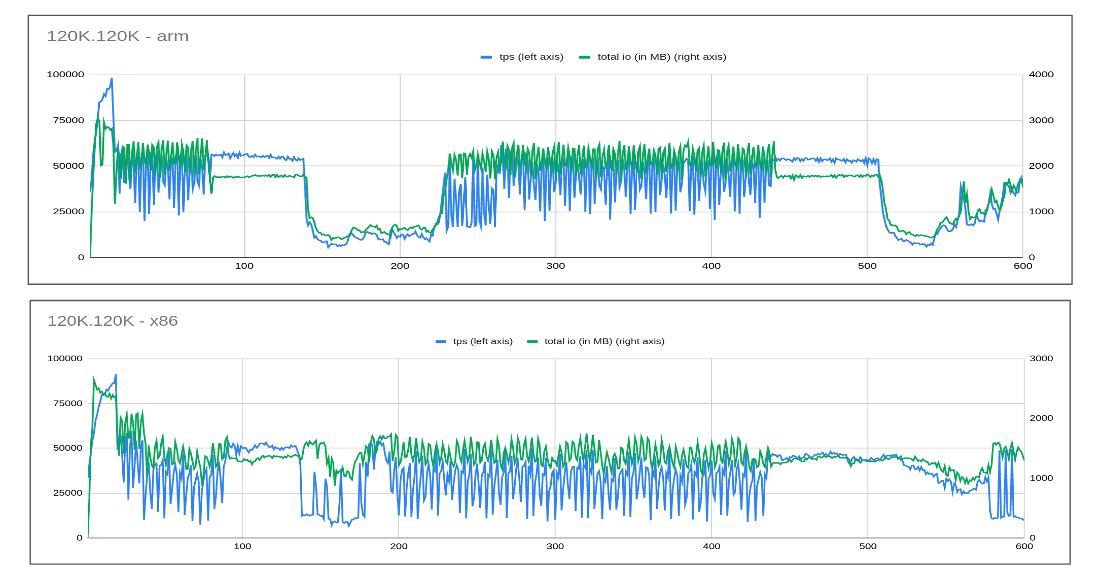
- So despite giving the maximum possible IO bandwidth, jitter in performance continues. In fact, the server did consume considerable IO bandwidth with the average hitting around 2-2.5 GB/sec (for ARM), 1-1.5 GB/sec (for x86).
Understanding what is going wrong
-
By increasing the innodb_io_capacity, we were providing more bandwidth to the flushing algorithm to ensure that the redo log threshold is not hit but we forgot the fact that with IO workload, LRU flushing has a big role to play.
-
Also, the innodb_io_capacity limit is meant for normal flushing but LRU flushing doesn’t respect the said limit. Instead, there are different parameters to control how many pages LRU flushing will flush. Tunning these limits will ensure that there are enough free pages available beforehand to load a new page.
-
One may wonder LRU flushing is even enabled in the above scenarios but we still see the jitter in performance. Let’s understand an important parameter
innodb_lru_flush_size. When the LRU flushing algorithm needs to flush it will flush innodb_lru_flush_size pages in a single invocation. The default value of this parameter is 32 pages. Even though the running transaction needs only 1 page, more are freed so that other threads don’t need to wait. Unfortunately, just 31 extra pages for 512 active threads is a big mismatch, and this kind of turns into each thread invoking a cycle of LRU flush. LRU flush cycle involves flushing a page to disk in-turn involvement of doublewrite buffer too and more mutex contention. This increases the latency of the LRU flush with jitter in performance.
Playing around with innodb_lru_flush_size
Let’s experiment with different innodb_lru_flush_size starting with 512 (1 multiple), 1024 (2 multiples), 2048 (4 multiples), 4096 (8 multiples), etc… This way LRU flush will ensure that there is at least 1 free page per thread and also help reduce the LRU latency with fewer double-write buffer invocations.
Also, let’s restore the value of innodb_io_capacity and innodb_io_capacity_max back to 12K/24K as even with these values REDO log was kept in check (without causing a flush storm of furious flushing).
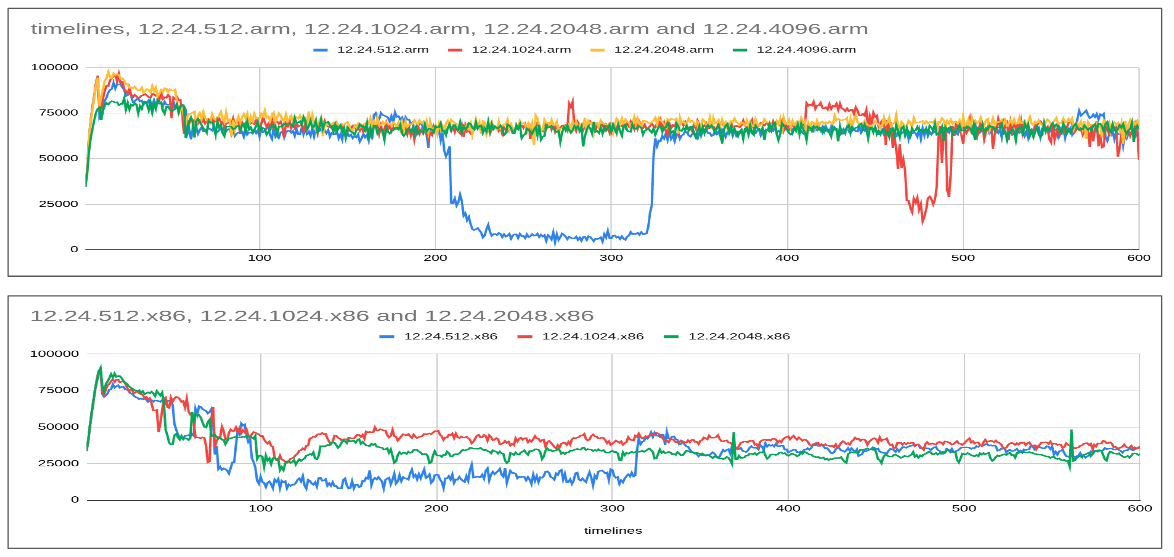
- It is evident from the graph above that the optimal size for innodb_lru_flush_size is 2048 for ARM (increasing it beyond that doesn’t help) and 1024 for x86 (2048 has slightly lesser tps).
- Also, it is interesting to note that despite giving the same resources for ARM and x86, ARM IO-bound workload performs way better than x86 with a significant margin (71K (ARM) vs 36K (x86)).
Does this increases the overall IO
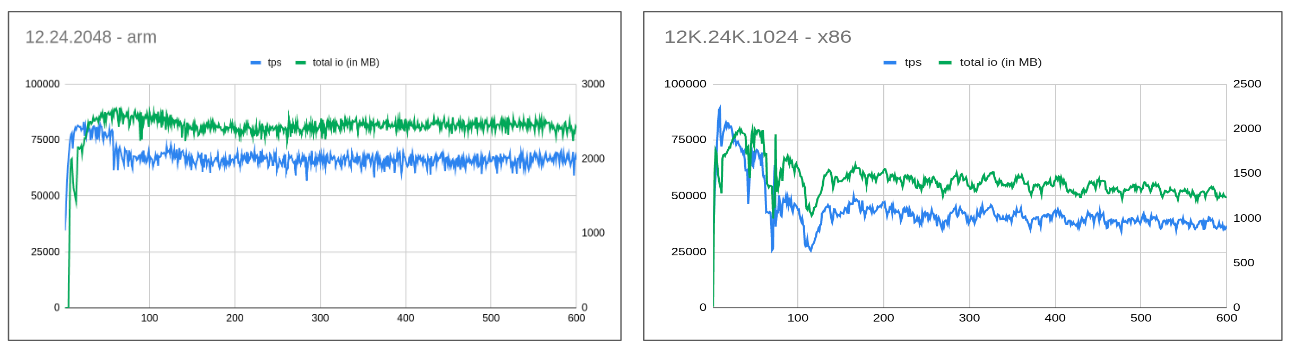
- Overall io continues to remain at the around same level (capped at around 2.5 GB/sec for ARM and 1.5 GB/sec for x86).
- So with the said tuning, we ensured the right things are made available at the right time that helps improve the overall performance.
Flipside
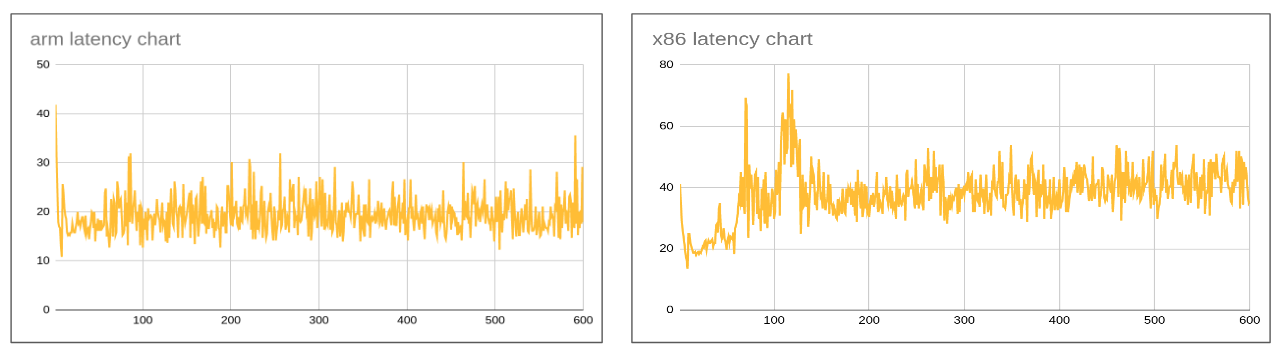
With an increase in innodb_lru_flush_size from the default of 32 to 2048, the latency of the thread that invokes LRU flush would be slightly higher during the transaction that causes LRU flush to invoke. Assuming all threads has equal chances of invoking LRU at regular interval the latency should amortize as we could see from the graph above.
What about innodb_lru_scan_depth
Definition of innodb_lru_scan_depth as per the documentation.
Specifies how far down the buffer pool least-recently-used (LRU) list the cleaning thread should look for dirty pages to flush.
But the said condition should be read with innodb_lru_flush_size as it exists in the code.
n->flushed + n->evicted [total-pages freed by this batch] < max [batch limit (innodb_lru_flush_size)] &&
UT_LIST_GET_LEN(buf_pool.free) [free pages but the value is dynamically changing with consumption active in background] < free_limit [innodb_lru_scan_depth]
So this means:
- If innodb_lru_flush_size pages are freed then the batch will end OR
- If free-pages > innodb_lru_scan_depth batch will end.
But tuning innodb_lru_scan_depth is difficult given it is linked to dynamically changing free-list length. Say user set innodb_lru_scan_depth = 1024. So once 1024 pages are freed batch should end but it is quite possible that after freeing 900 pages 200 get pined and the free count drops down to 700 and the batch continues to work further (increasing latency of the invoking thread).
So it is advisable to keep innodb_lru_scan_depth > innodb_lru_flush_size so that each batch will free up at least innodb_lru_flush_size and will end. Dynamically changing buf_pool.free limit makes it difficult to set a good value for innodb_lru_scan_depth. Also, I see the documentation or interpretation as a misnomer now. Maybe originally, variable semantics was inline but as per the existing condition, it is better to tune innodb_lru_flush_size.
Conclusion
While tuning of an IO workload it is important to keep a watch on all facets of IO viz. normal flushing (meant for redo log), LRU flushing to ensure enough free pages are available, etc.. From the experiment, it is quite evident that setting innodb_lru_flush_size to 2/4 multiples (of scalability) helps in improving performance with less jitter (without increasing IO).
If you have more questions/queries do let me know. Will try to answer them.